
先日のVFV2まとめの中でもご紹介した「Voiceflow SDK」、もう少しすると公式に提供されるはずですが、ややフライング気味にLINE BOTを実装してみました。
目次
Voiceflow SDKとは?
元々、Voiceflowは、Amazon AlexaスキルおよびGoogleアクションをノンコーディングで作成し、それぞれのプラットフォーム(AlexaであればAmazon Echo、GoogleであればGoogle HomeやGoogleアシスタント)で公開するためのツールでしたが、昨年、これらのプラットフォームに依存しないカスタムなアシスタントを作成することができるようになりました。
ただし、このカスタムアシスタントは公開用のプラットフォームを持ちません。これを可能にするのがVoiceflow SDKです。
Voiceflow SDKを使うと、Voiceflowで作った対話モデルとチャットボットプラットフォームを中継するアプリケーションを開発することができ、ひとつの会話フローをさまざまなチャットボットプラットフォームに対応させることができます。
ということで、今回はLINE BOTと連携させてみました。
サンプルコードとアーキテクチャ
まずはサンプルコードで実際に動いているものを見てもらうのが早いでしょう。サンプルコードは以下のgithubレポジトリで公開しています。
今回はサンプルなので、LINE Messaging API SDK/Voiceflow SDKを使ったNode.jsアプリをローカルに立ててngrokで公開、それをLINE Messaging APIのwebhookに指定しています。
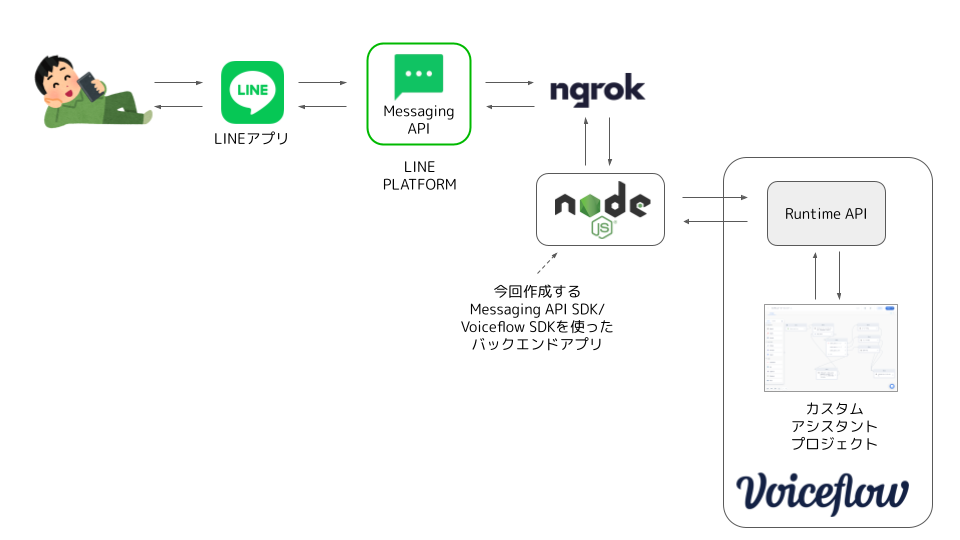
事前準備
サンプルアプリの実行には以下が必要です。
- node.js実行環境
- ngrok
- LINE BOTの設定
- Voiceflowのカスタムアシスタント向けサンプルプロジェクト
- VoiceflowプロジェクトのバージョンID
- VoiceflowのAPIキー
上記のうち、1〜3については説明を割愛します。ググって準備してください。
少し補足します。
- Voiceflow SDK(Voiceflow Runtime Client)は、将来的には複数言語に対応するようですが、現時点ではJavaScript用だけのようですので、node.js実行環境が必要になります(LINE BOT用のSDKもnode.jsに対応しています)
- LINE BOTの設定では、「チャネルシークレット」と「チャネルアクセストークン」を取得して、BOTと友達になっておいてください。なお、Webhook URLは後で設定しますので、一旦ダミーのものを登録しておけば良いと思います。
4〜6はVoiceflow SDKを使うために必要ですので、後で説明します。
サンプルアプリの実行
レポジトリのclone
上記のサンプルレポジトリをcloneしておいてください。
$ git clone https://github.com/kun432/voiceflow-line.git && cd voiceflow-line
Voiceflowのカスタムアシスタント向けサンプルプロジェクト
前提として、Voiceflow SDKは現在、カスタムアシスタント向け専用で、Alexa/Google向けには使えないようです。この点に注意してください。
今回用意したサンプルは、以下のAlexa向けVoiceflow日本語チュートリアルでも使っている「コーヒーショップ」スキルを元に、カスタムアシスタント向けに修正したものです。
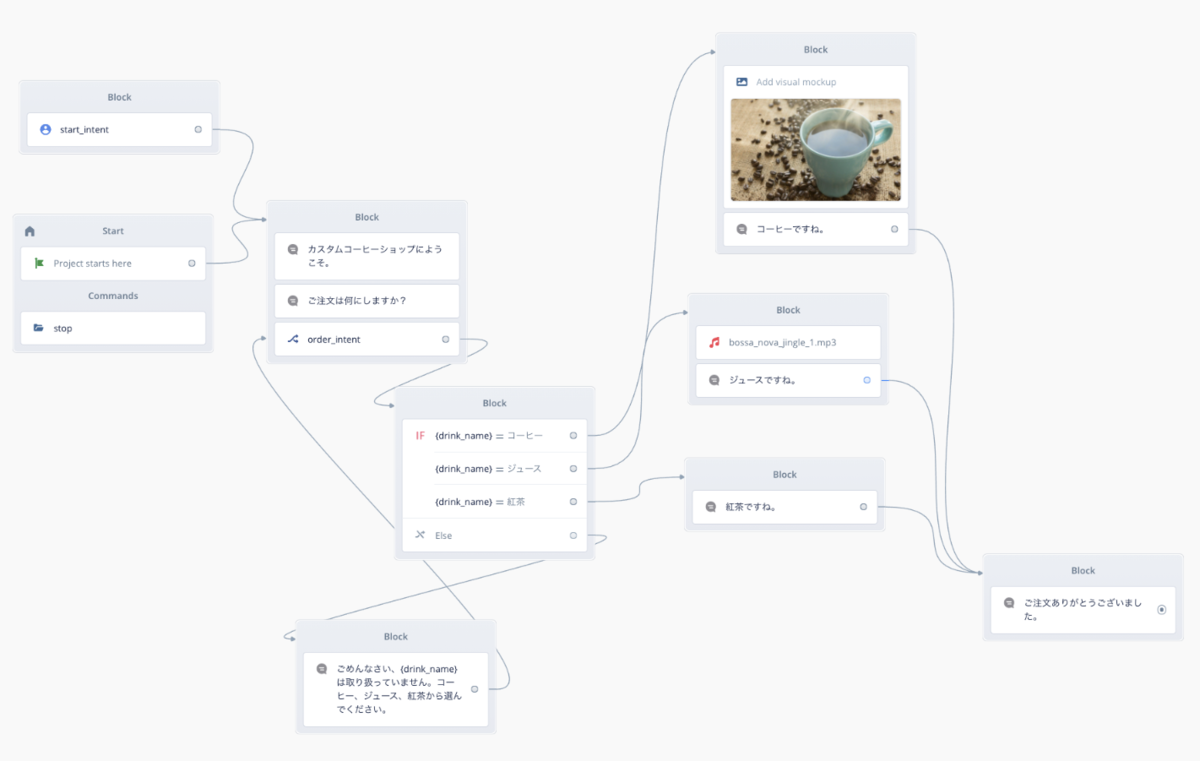
このプロジェクトをエクスポートしたcoffeeshop.vfファイルがcloneしたレポジトリフォルダの中にありますので、これをVoiceflowにインポートしてください。インポートはプロジェクト一覧画面の右上のアイコンです。
.vfファイルを指定すると、現在開いているワークスペース上にプロジェクトがインポートされます。
インポートされたらプロジェクトを開いて、一度テストを開いてください。右上の"Test"をクリックします。
対話モデルを学習させます。"Train Assitant"をクリックします。
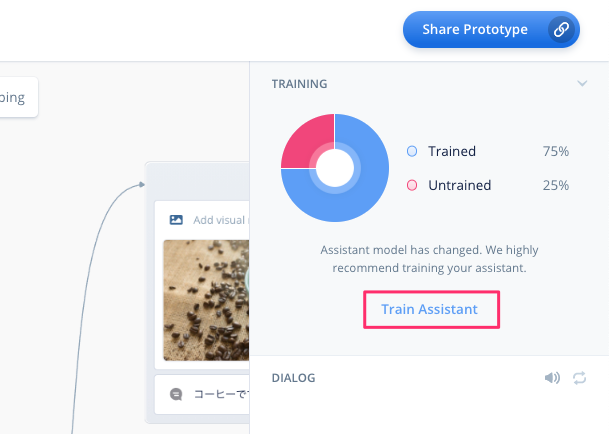
以下のように"Trained"が100%になっていればOKです。
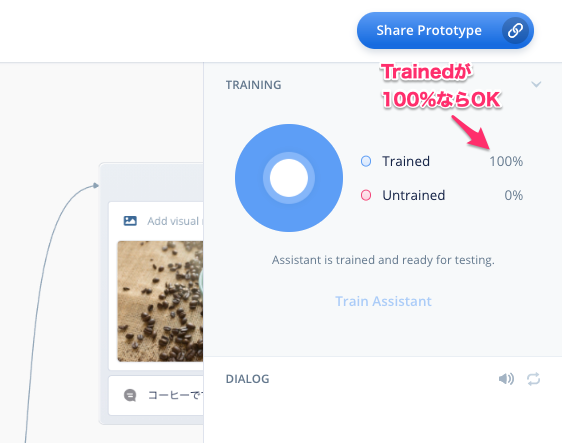
終わったら左上の"Back"をクリックして、プロジェクトの編集画面に戻ります。
バージョンID
次にバージョンIDです。バージョンIDはプロジェクトのURLから取得できます。
現在プロジェクトの編集画面が開いていると思いますので、ブラウザのURL欄を見てください。
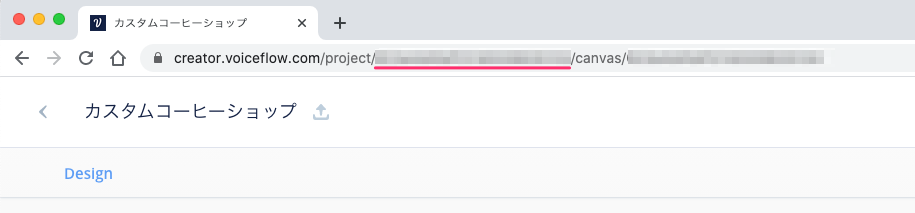
"https://creator.voiceflow.com/project/XXX...XXX/canvas/XXX...XXX"というようなURLになっていると思います。この"project/"と"/canvas"の間のランダムな文字列がバージョンIDになります。これをどこかに控えておきましょう。
APIキー
次にAPIキーです。APIキーは、近々専用の管理画面ができるようですが、現状はありませんので、少しひねったやり方になります。
プロジェクトの編集画面の左上の"<"をクリックして、インポートしたサンプルプロジェクトが存在するワークスペース画面に戻ります。
ワークスペース画面が表示されました。
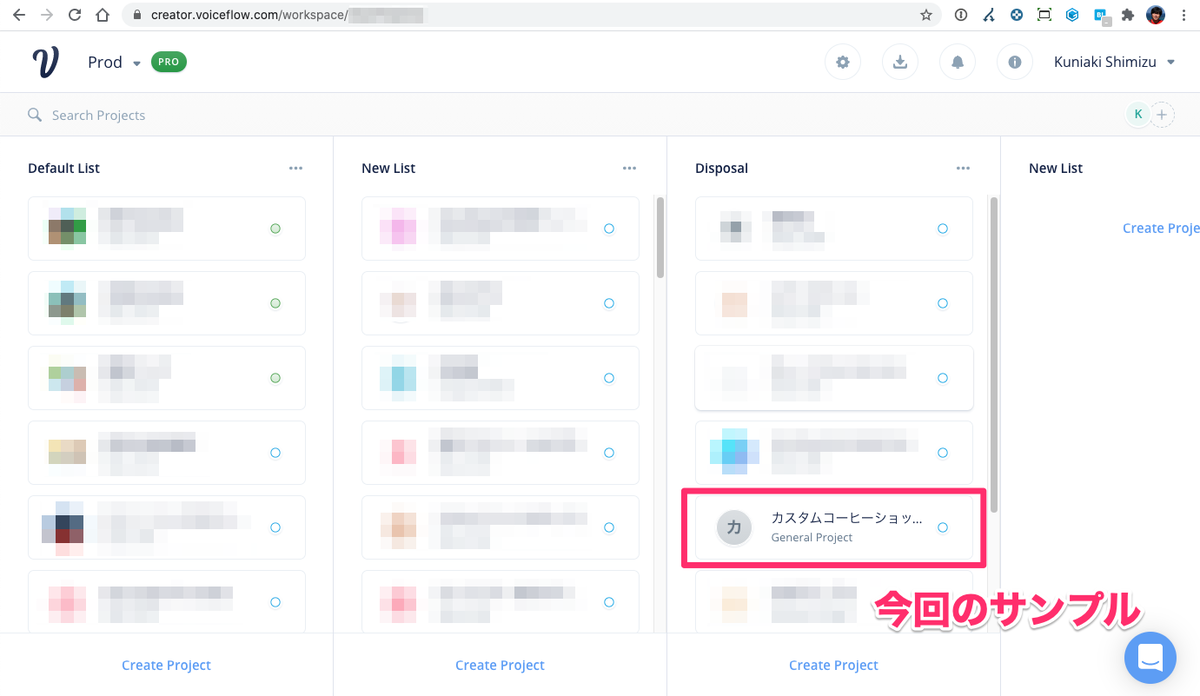
このとき、ブラウザのURL欄を見てください。"https://creator.voiceflow.com/workspace/" のあとにランダムな文字列が並んでると思います。
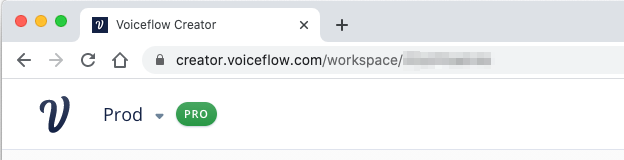
URLの最後に"/api-keys" を追加してアクセスします。
APIキーの管理画面が表示されました。ここで"Create New API Key"をクリックします。
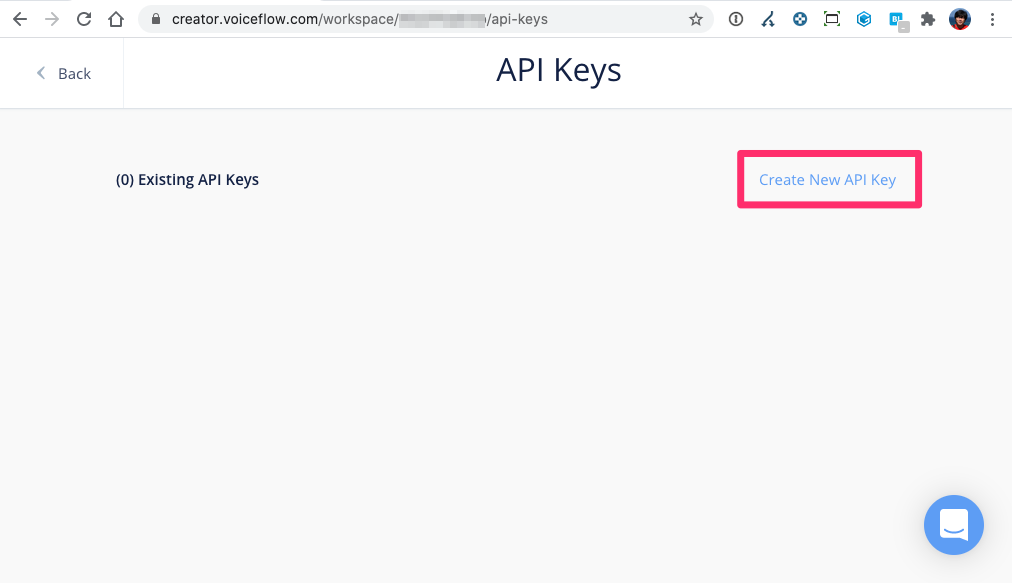
APIキーの名前を入力します。今回はテストなので適当に入れました。"Confirm"をクリックします。
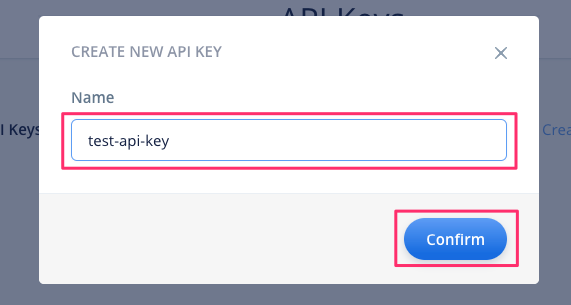
"Successfully Created"と表示されればOKです。"VF." で始まる文字列がAPIキーになります。セキュリティの観点から、この画面を閉じるとAPIキーは二度と表示されません。"Copy to Clipboard"をクリックするとコピーされますので、安全なところに保管しておきしょう。
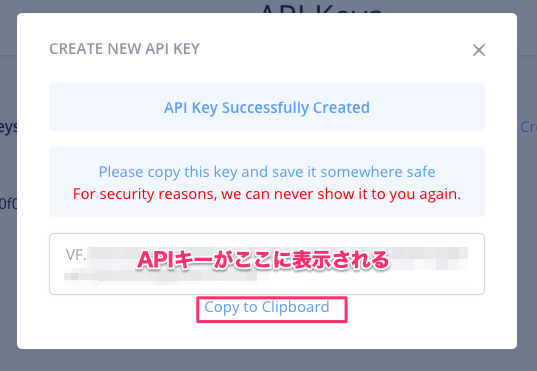
APIキー管理画面に戻ると、APIキーが表示されていますが、全部は表示されていませんね。もしコピーするのを忘れた場合は、このキーを削除して、新しいキーを生成してください。Backボタンで戻ります。
これで必要な情報が揃いました。
サンプルアプリの起動
ではサンプルアプリを起動します。
まず必要なパッケージをnpm installでインストールします。これでVoiceflowとLINE BotのSDK、およびnode.jsのwebサーバであるexpressがインストールされます。
$ npm install
次にこれまでに取得した各種情報を環境変数に設定していきます。"XXXXX...XXXXX"はそれぞれ用意したものに置き換えてください。
# LINE BOTのチャネルアクセストークン $ export CHANNEL_ACCESS_TOKEN="XXXXX...XXXXX" # LINE BOTのチャネルシークレット $ export CHANNEL_SECRET="XXXXX...XXXXX" # VoiceflowのサンプルプロジェクトのバージョンID $ export VF_VERSION_ID="XXXXX...XXXXX" # Voiceflowのサンプルプロジェクトが存在するワークスペースのAPIキー $ export VF_API_KEY="VF.XXXXX...XXXXX"
ではアプリを起動します。
$ node .
listening on 3000
上記のように"listening on 3000"と表示されればOKです。3000番ポートでアプリが起動していることになります。
ngrokの起動
次に、ngrokを使って、さきほど起動したアプリをインターネット側からアクセスできるようにします。別のターミナルを立ち上げて以下を実行します。
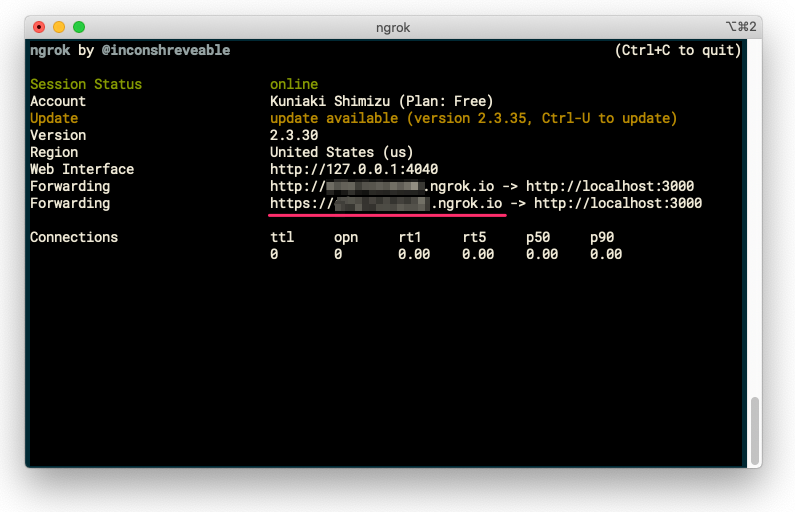
$ ngrok http 3000
これにより、ngrokが3000番ポートで起動しているアプリにトンネルを用意して、インターネット側からアクセスできるURLを発行してくれます。以下の真ん中に表示されている"https"で始まる https://XXXXXXXXXX.ngrok.io というのがそのURLです。これをメモしておいてください。
LINE BOTのWebhookの設定
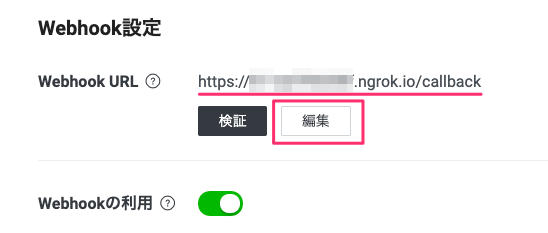
最後に、ngrokで発行されたURLをLINE BOTのWebhook URLとして設定します。LINE Developersコンソールの該当のBOTの「Messaging API設定」の中にある「Webhook URL」の「編集」をクリックします。
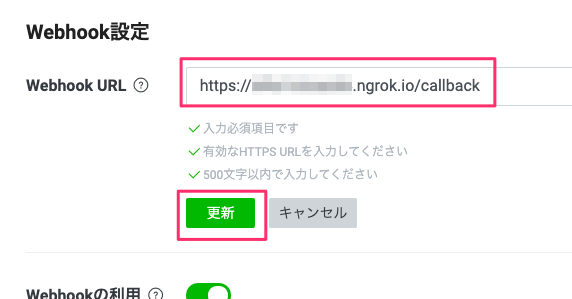
ここに、先程取得したngrokのURLを入力し、末尾に/callbackを追加します。設定したら「更新」をクリックします。
なお、ngrokは終了してしまうとそのURLは無効になり、再度起動すると違うURLが発行されます。したがって、このWebhook URLも変更する必要が出てきますので、ご注意ください。
テスト
ではLINEアプリを立ち上げて、「注文する」とか「開始」と入力してみてください。以下のように応答が返ってくれば成功です。
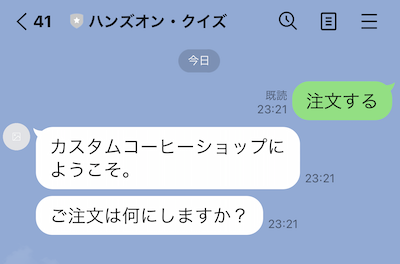
「コーヒー」「ジュース」「紅茶」で分岐するようにしていますので、色々入力してみてください。シノニムやサンプル発話も少しですがバリエーションを登録してありますので、言い方を変えてみてください。
画像を表示したり、
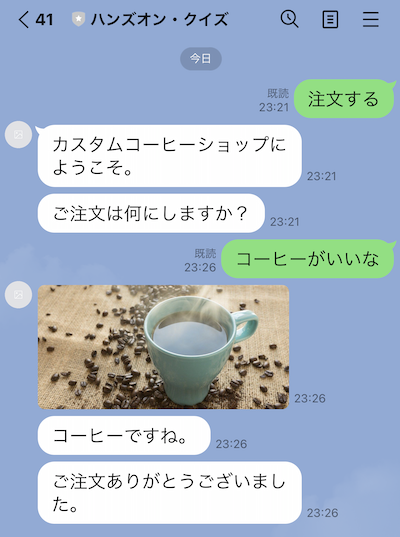
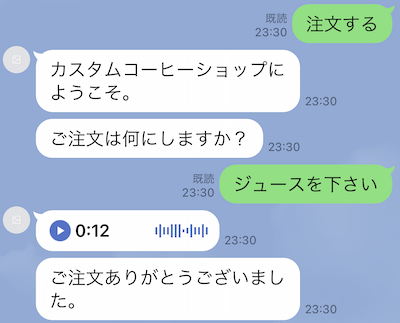
オーディオを再生することも可能です(ただし自動再生はされません)
プロジェクトを変更する
LINE BOTが動くようになったところで、少しプロジェクトを変更してみましょう。最初のSpeak Blockのメッセージを修正します。修正後に、Voiceflow上で一度テストして変更されていることを確認しておいてください。
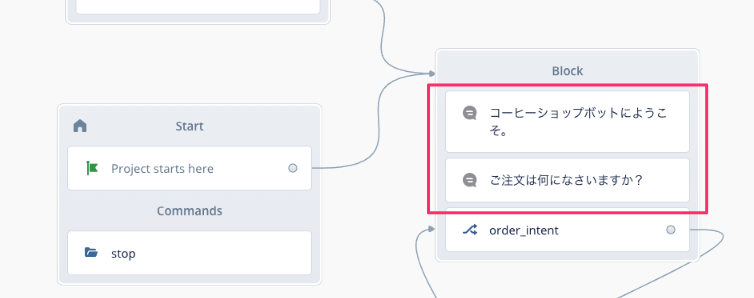
再度BOTに注文してみましょう。

変更されているのがわかるでしょうか?つまり、VoiceflowのGUI上での変更が即座に反映されるということですね!
サンプルコード
少しだけサンプルコードについて。ちゃんと理解できてるか怪しいですが、説明してみます。
LINE公式のオウム返しBOTのサンプルコードをベースにしています。ユーザから送信されたメッセージの文字列をそのままレスポンスとして返すというものです。
これをVoiceflow SDKと組み合わせて、以下のようなやり取りになるように修正しています。
- ユーザがLINEアプリで送ってきたメッセージを取得
- このメッセージをVoiceflow SDK経由でVoiceflowプロジェクトに送信
- Voiceflowプロジェクトが会話フローに従って応答したものを取得
- Voiceflowプロジェクトからの応答をLINEの応答フォーマットに合わせて整形して、ユーザに返答
単にやりとりを中継しているだけのとてもシンプルなものです。
順に見ていきます。LINE BOT SDKの説明はちょっと割愛します。
Voiceflow SDKを呼び出します。
const { default: RuntimeClientFactory, TraceType } = require("@voiceflow/runtime-client-js");
環境変数からVoiceflowプロジェクトのバージョンIDおよびワークスペースのAPIキーを取得します。
const vfconfig = {
versionID: process.env.VF_VERSION_ID,
apiKey: process.env.VF_API_KEY,
};
Voiceflow SDKとは直接関係ありませんが、オンメモリなデータベースへのアクセスを用意して、ユーザのセッション状態(現在会話セッションが継続しているか?)を管理できるようにしてあります。
// mock database
const mockDatabase = {};
const db = {
read: async (userID) => mockDatabase[userID],
insert: async (userID, state) => mockDatabase[userID] = state,
delete: async (userID) => delete mockDatabase[userID]
};
VoiceflowプロジェクトのバージョンIDおよびワークスペースのAPIキーを使って、Voiceflowクライアントを作成するためのfactoryインスタンスを作成します。
// create VF SDK client const runtimeClientFactory = new RuntimeClientFactory(vfconfig);
ここからはLINEアプリ経由でユーザが送ってきたメッセージの処理です。
- ユーザのメッセージ送信などで送信されていたイベントから、「ユーザID(event.source.userId)」「メッセージの文字列(event.message.text)」を取得します。ユーザIDはセッション状態を管理するためのキーになります。
- セッションデータベースからユーザのセッション状態を確認します。通常初回はセッションがないはずなのでstateは空になりますが、セッション中の場合はVoiceflowから返されたセッション状態をここに保存し、リクエストのたびに呼び出すことでセッション状態を管理します。
- VFのfactoryインスタンスのcreateClient()メソッドを使って、VFクライアントインスタンスを作成します。これが実際にVoiceflowとやり取りするためのインタフェースになります。createClient()メソッドにstateを渡すことでVoiceflow側とのセッション状態を維持します。
- VFのクライアントインスタンスのsendText()メソッドで、LINEから送信されたメッセージをVFに送信します。Voiceflowからのレスポンスはcontextオブジェクトに入ります。
const userId = event.source.userId; const userInput = event.message.text; const state = await db.read(userId); const vfclient = runtimeClientFactory.createClient(state); const context = await vfclient.sendText(userInput)
Voiceflowからのレスポンスをチェックして、会話セッションが終了しているかを確認します。終了している場合はセッションデータベースからユーザセッションを削除します。会話が継続中の場合はレスポンス中に含まれるセッション状態をデータベースに保存し、以降のやり取りで使います。
if (context.isEnding()) {
db.delete(userId);
} else {
await db.insert(userId, context.toJSON().state);
}
ちなみにVFからのレスポンスは以下のような配列に各オブジェクトが入っている形になっています。よく見るとVoiceflow上で実行される会話フローの各ブロックや処理などが順番に並んで返されるようです。したがって、この中から必要なものだけを抽出して応答に使うような感じになります。
[
{
"type": "debug",
"payload": {
"message": "matched intent **start_intent** - confidence interval _92.48%_"
}
},
{
"type": "block",
"payload": {
"blockID": "start00000000000000000000"
}
},
{
"type": "debug",
"payload": {
"message": "matched command **jump** - jumping to node"
}
},
{
"type": "block",
"payload": {
"blockID": "60439a9214ce235bc900f839"
}
},
{
"type": "speak",
"payload": {
"message": "カスタムコーヒーショップにようこそ。"
}
},
{
"type": "block",
"payload": {
"blockID": "605365085fd8e1ef16862953"
}
},
{
"type": "debug",
"payload": {
"message": "evaluating path 1: `({sessions} == 1)` to `false`"
}
},
{
"type": "debug",
"payload": {
"message": "no conditions matched - taking else path"
}
},
{
"type": "block",
"payload": {
"blockID": "605365485fd8e1ef1686296e"
}
},
{
"type": "speak",
"payload": {
"message": "またご来店いただきありがとうございます。"
}
},
{
"type": "block",
"payload": {
"blockID": "6051f1d16578cc1a9619c328"
}
},
{
"type": "speak",
"payload": {
"message": "ご注文は何にしますか?"
}
},
{
"type": "block",
"payload": {
"blockID": "604b9982bbafd948885abec5"
}
},
{
"type": "choice",
"payload": {
"choices": [
{
"name": "紅茶"
},
{
"name": "ジュース"
},
{
"name": "コーヒー"
}
]
}
}
]
セッションが終了する場合のレスポンスは以下のようにtype: endが入っているものになります(わかりやすいように不要なものは除いてます)。isEnding()はこれが含まれているかをチェックしているわけです。
{
"type": "speak",
"payload": {
"message": "またのご来店をお待ちしております。"
}
},
{
"type": "end"
},
]
先ほど説明したとおり、VFからのレスポンスはいろんなブロックの処理や応答が配列で渡ってきますので、これを順次取り出すことになります。ユーザに実際に返されるレスポンスで使うのは以下の3種類のオブジェクトになるかと思います。
- TraceType.SPEAK
- TraceType.VISUAL
- TraceType.AUDIO
これ以外にもTraceType.DEBUGというデバッグ用のものや、TraceType.CHOICEというサジェスチョンチップのためのオブジェクトもありますが、一旦割愛します。
これらのオブジェクトのタイプに合わせてペイロードからデータを取り出し、LINEのレスポンスフォーマットにあわせて整形しているのが以下です。
let replyMessages = [];
for (const trace of context.getTrace()){
if (trace.type === TraceType.SPEAK) {
replyMessages.push({
type: 'text',
text: trace.payload.message
});
}
if (trace.type === TraceType.VISUAL && trace.payload.visualType === 'image') {
replyMessages.push({
type: 'image',
originalContentUrl: trace.payload.image,
previewImageUrl: trace.payload.image
});
}
if (trace.type === TraceType.AUDIO) {
replyMessages.push({
type: 'audio',
originalContentUrl: trace.payload.src,
duration: 12000 // need to know the duration of audio in advanced...
});
}
}
上で少し紹介しましたが、3種類のオブジェクトの実際の応答を見てみましょう。まずはTraceType.SPEAK。
{
"type": "speak",
"payload": {
"message": "カスタムコーヒーショップにようこそ。"
}
},
TraceType.VISUALやTraceType.AUDIOの場合はそれらのURLが返ってくるわけですね。
{
"type": "visual",
"payload": {
"visualType": "image",
"image": "https://s3.amazonaws.com/xxxxxxxxxxxxxx/xxxxxxxxxxxxxxxxxx.jpg",
"device": null,
"dimensions": null,
"canvasVisibility": "full"
}
{
"type": "audio",
"payload": {
"message": "",
"src": "https://s3.amazonaws.com/xxxxxxxxxxxxx/xxxxxxxxxxxxxxxxxx.mp3"
}
},
こういったものをよしなに整形した後、最後にまとめてLINE BOTの応答として返して終わりです。
return client.replyMessage(event.replyToken, replyMessages);
まとめ
ということで、Voiceflow SDKを使って、LINE BOTを動かしてみました。ちょっと手探り感もあったのですが、いざやってみるととてもシンプルで少ない労力で書けますし、いろいろな可能性が広がると感じています。
- いろんなプラットフォームにあわせて書き換えることでマルチに展開できる。
- 会話のロジックやフローはVoiceflowのプロジェクトに集約されるので、これだけを管理すれば良い。
- デザイナーは直接的かつ親しみやすいGUIで会話デザインに集中、プログラマーはインフラスタックの選択や運用、各プラットフォームごとの対応などに集中、デザインとプログラミングの分業ができる。
ぜひサンプル動かしてみていただいて体感していただければと思いますし、今後も楽しみです!
公式のレポジトリにはいろんなサンプルやドキュメントなどもありますので、そちらも見てみてください。