
Voiceflowでやってみるシチュエーショナルデザインの第2回です。今回は「パーソナライズする」がテーマです。パーソナライズは、対話デザインで行うものと、実際に何らかのデータと連携するような技術的な要素が必要なものがありますが、前者を中心にまとめます。
Alexa道場のシチュエーショナルデザインの回はこちら
シチュエーショナルデザインの日本語ドキュメントは以下にあります。
この記事は「Voiceflowでやってみるシチュエーショナルデザイン」シリーズの第2回の記事です。他の記事は以下にあります。よろしければあわせて読んでみてください。
第1回
第3回 Part1
第3回 Part2
第4回
新規ユーザーと2回目以降のユーザーを識別する/スキルの使用を通じて情報を取得する
現実にもありますが、とあるお店によく通うにつれて、店員さんに前回買ったものを覚えていてもらえたり、より親密に話しかけてもらえたりするとうれしいですよね。ここでは、スキルを使う頻度に合わせて、発話を変えてみたり、ユーザの前回の発話内容を覚えていたり、という言うのをやってみます。
公式ドキュメントにある「お菓子フレンド」を題材に、まず、初回実行時の発話をイメージしたサンプルを作ってみました。

スキルが起動したら、最初にスキルの説明をして、その後、作りたいデザートの名前を聞く感じにしてます。
デザート名を聞くdessert_intentはこんな感じです。ユーザが発話したデザート名を"dessert_name"というスロットで受け取っています。


実際に動かしてみましょう。

では、2回目の発話フローを作ってみましょう。Voiceflowでは"{sessions}"という最初から用意されている変数にスキルの起動回数が記録されていますので、これをチェックするだけで初回と2回目がチェックできます。
Home Blockと最初のSpeak Blockの間にCondition Block(以前はIF Blockと呼んでました)をおいてつなげてください。

Condition Blockの設定を以下の通りに設定します。
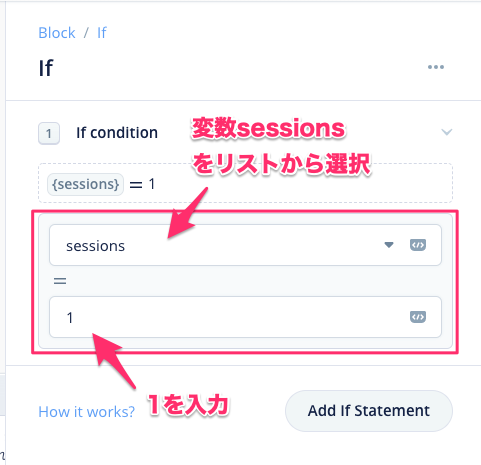
入力し終わったらブロックを見てみましょう。"IF {sessions} = 1" となっていますね。つまり「もし変数sessionsが1ならばこのフローに流れる」という条件分岐がこれでできたということです。

で、下にあるElseは「それ以外」という意味になりますので、ここでは初回以外、すなわち「2回め以降」ということになります。2回目以降の発話を想定したSpeak Blockをこんな感じで置いてつなげてみます。

実はもう一つここでは仕込んであるのですが(多分わかってる人もいると思います)、あとで説明しますね。ではこれでテストしてみましょう。
テストの前に、このsessionsという変数はVoiceflowの内部で管理されていますので、Voiceflow上から意図的に値をリセットしたりすることができません。値をリセットする場合には、Alexa開発者コンソールのテストシミュレータの左上にある「スキルテストが有効になっているステージ」を、「開発中」から「非公開」にして、再度「開発中」にすることでリセットできます。


はい、テストです。2回連続で起動してみます。

1回目と2回目でセリフが変わっているのがわかりますよね。このようにしてsession変数を使うことで、ユーザの実行回数に応じてメッセージを切り替えることができます。
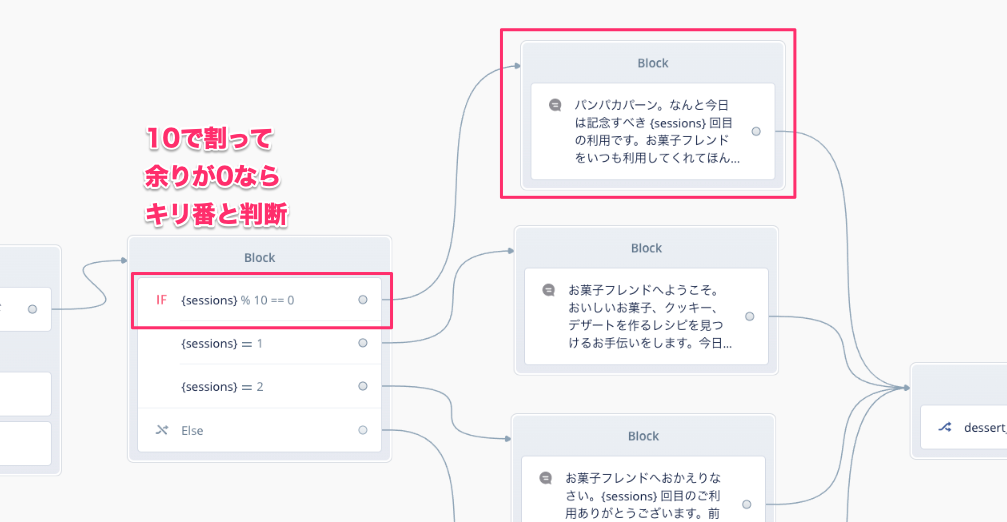
更に条件を細かく追加して初回・2回目・3回目以降みたいにしたり・・・

少しひねって10回ごと・100回ごとといったキリ番の時になにか特別なメッセージを流したり、ということもできるので、色々考えてみてください。
Condition Blockに複数の条件を書く場合、上から順番に評価され、合致したものがあればそこで評価は終了し、次のブロックに流れます。複数の条件に合致するような場合には順番に気をつけてください。
それともう一つ、1回目で伝えた名前とレシピ名が2回目でそのまま話されているのがわかりますか?

Voiceflowでは、変数やスロットに保持した値はセッションが終わっても記録されます(これを「永続的」といいます)。これを使うと、ユーザはAlexaがユーザ自身のことを覚えていてくれると思うようになり、Alexaをより親密に感じることができますね!
逆に言うと、セッションごとにクリアされるような変数を使いたい場合にはこれだとまずいので、スキル起動直後にSet Blockで変数を初期化するか、flow変数というものを使う必要があります。詳しくは以下をご覧ください。(昔の記事なので画面等はちょっと古いままです、ごめんなさい)
状況に応じたセリフを使用する
ユーザはスキルを使いなれていくと、ちょっとしたことが長ったらしく感じたり、同じセリフの繰り返しが気になるようになります。上でご紹介したのと少し似ていますが、利用頻度に応じて、慣れたユーザの使い方に沿うように返答を変化させる必要があります。
例えば、上の例の1回目と2回目の違いを見てください。


1回目は初めてスキルを使うユーザのために、このスキルが何をしてくれるのかを説明しています。2回目の場合は、すでにこのスキルがレシピを教えてくれるということは知っているので、スキルの説明はしていませんよね。さらに何十回と使っていくうちに、もっとダイレクトにレシピを知りたいと思うかもしれません。そうなった場合はもっと短くしたほうがいいかもしれませんね。
また、常に決まったセリフの繰り返しだと、いかにも定型的でユーザは飽きてしまうかもしれません。その場合、上でご紹介したようにsessions変数を使って話す内容を変えたりするのは一つのやり方ですが、ここではそれに加えてAlexaからの発話をランダムにさせてみましょう。ランダムにするのは、決まった発話しかしない一番最後のSpeak Blockにします。

まず、最初と同じようにCondtion Blockで回数ごとに言い方を変えるようにしましょう。もう一度Condtion Blockの設定をしてもいいのですが、Voiceflowではブロックのコピー・ペーストができるので、これを利用して楽をしましょう。
Condition Blockを右クリックするとメニューが表示されるので、"Copy Block"をクリックします。

クリップボードにコピーされたことが表示されればOKです。

次に、dessert_intentのChoice Blockと最後のSpeak Blockの少し下あたりで右クリックします。するとまたメニューが表示されるので"Paste"をクリックします。

はい、Condition Blockが複製されました。
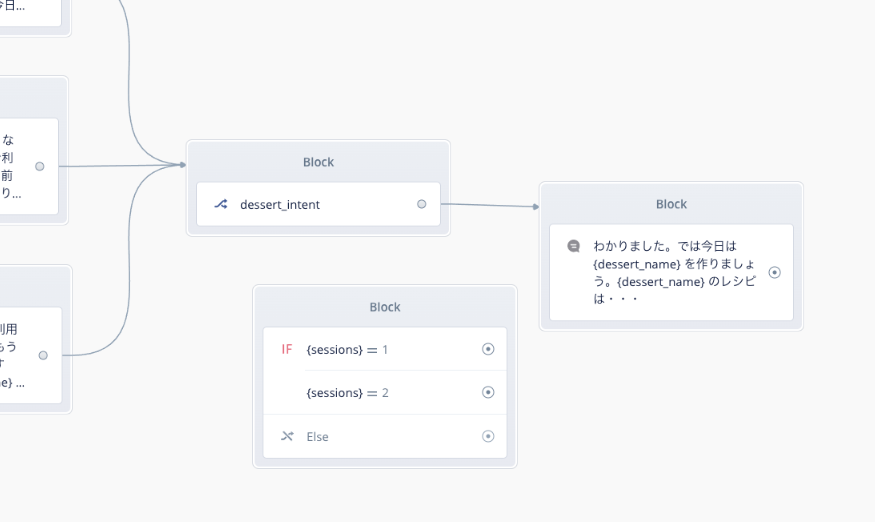
複製したConditionをこんな感じで線をつなぎ直します。1回目と2回目はとりあえず同じセリフを発話する感じにしておきます。

ランダムにするのは3回目以降の発話にしましょう。Speak Blockを一つおいてElseからつなげます。

Speak Blockの設定です。こんな感じで発話を入力して、下にある"System"というボタンをクリックします。

するとさらに入力欄が表示されますので、なにか少し違った発話内容を入力してください。

これを繰り返して、以下のような感じにします。

で、このままだと、上から順番に読み上げられることになるので、一番下の"…"をクリックします。
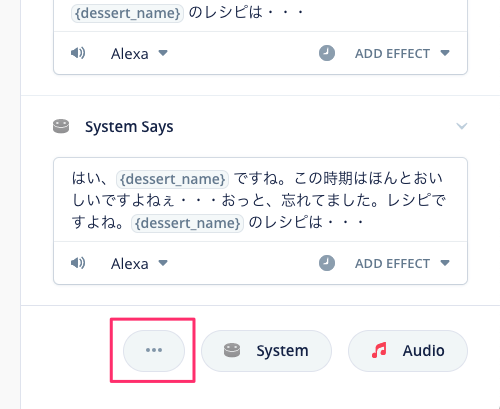
すると"Randomize outputs"というメニューが表示されますので、これをクリックします。

発話の横にアイコンが表示されていればOKです。これでこの発話の中のどれかがランダムで話されることになります。

ではテストしてみましょう。

3回目以降の応答がランダムになっているのがわかりますでしょうか。使い慣れたユーザでも飽きさせないようにしたいですね。
スキルの終了後にセッションを再開する
忙しいときなんかはスキルを途中で止めたい時ってありますよね。しばらくしてからもう一度スキルを実行して、また最初に戻ってやらないといけないというのは少し面倒です。できれば前回の続きからやってほしい。こういうのもパーソナライズになります。
実はVoiceflowは標準でこれに対応する「レジューム機能」があり、シンプルに設定をONにするだけで「前回の続きから再開しますか?」という感じで実行できていたのですが、今年に入って画面インタフェースが大幅に変わったこともあり、この設定も少し動きが変わっているようです。また別途まとめたいと思います。参考までに以前まとめた記事をご紹介しておきます。
ユーザーの位置情報にアクセスする
位置情報などのユーザ情報からパーソナライズを実現するやり方こともできます。これらについては技術的な内容も関連するので今回は割愛します。興味があれば、少し画面が古くなってしまってますが、以前ご紹介した記事を参考にしてください。
また、これらの情報は場合によっては個人情報にも関わるものもあります。その場合、Voiceflow上での変数の使い方やデータの保持の仕方なども含めて考慮が必要になってきますので、十分にそれを理解した上でご利用されることをおすすめします。
はい、ということでシチュエーショナルデザインの第2回「「2. パーソナライズする: 対話を個人に合わせて最適化すること」でした。個々のユーザごとの情報を記憶したり、ユーザの利用度合いに合わせて対話に変化をつけることで、よりユーザに親近感を与えることができます。ぜひやってみてください。
次回は「3. わかりやすくする:階層型のメニューではなく、すべてのオプションをトップに配置すること」です。
続きはこちら