Metabaseの続きです。
前回はデータソースの追加までやりました。今回は追加したデータソースを使って可視化していきたいと思います。
目次
サンプルデータベースについて&可視化のお題
サンプルデータベースの詳細は以下。
元をたどるとこちらですね。
知らなかったんですが、サンプルで用意したDVDレンタルのデータベース、これMySQLもPostgreSQLも同じものなのですね。見た感じ元々MySQL用が最初っぽい。MetabaseはMySQLも使えるのでMySQLでいきたい人は参考までに。
で、なにか練習用にお題ないかなーと思って探してたら、こういう記事がありました。
ありがたいですね。ではこの記事と同じことをMetabaseでやっていきたいと思います。
お題1: 特定の俳優が出演する映画
Qiitaの記事にある通り、
- Actorテーブルは映画のタイトル情報を持っていない
- Filmテーブルは出演者の情報を持っていない
- 出演者IDとタイトルを多対多で紐付けているのはFilm Actorテーブル
ということで、Film ActorテーブルにActorテーブル、FilmテーブルをJOINさせれば良さそうです。
右上の「+New」をクリックします。
SQLクエリを直接叩いてもいいのですが、SQLさっぱりわからんマンなので、GUIでやりましょう。「質問」をクリックします。

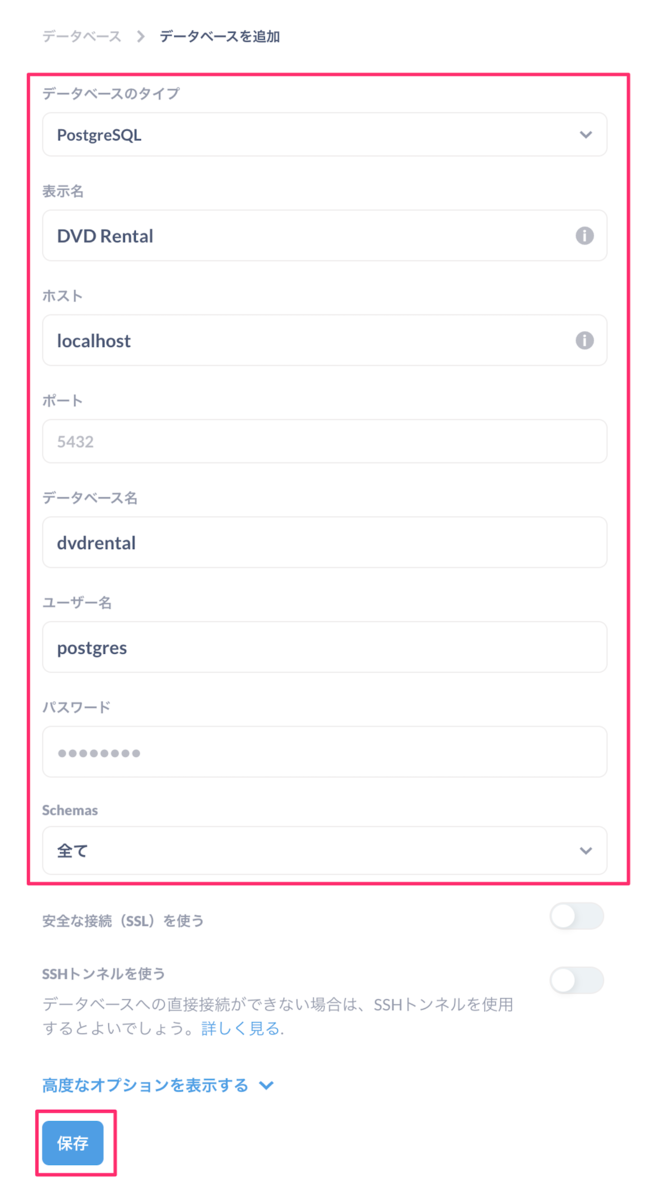
開始するデータとしてDVD Rentalデータベースを選択。
そしてFilm Actorテーブルを選択します。
Film Actorテーブルが選択された状態になります。ここで右の方にある再生ボタンのようなものをクリックしてみます。
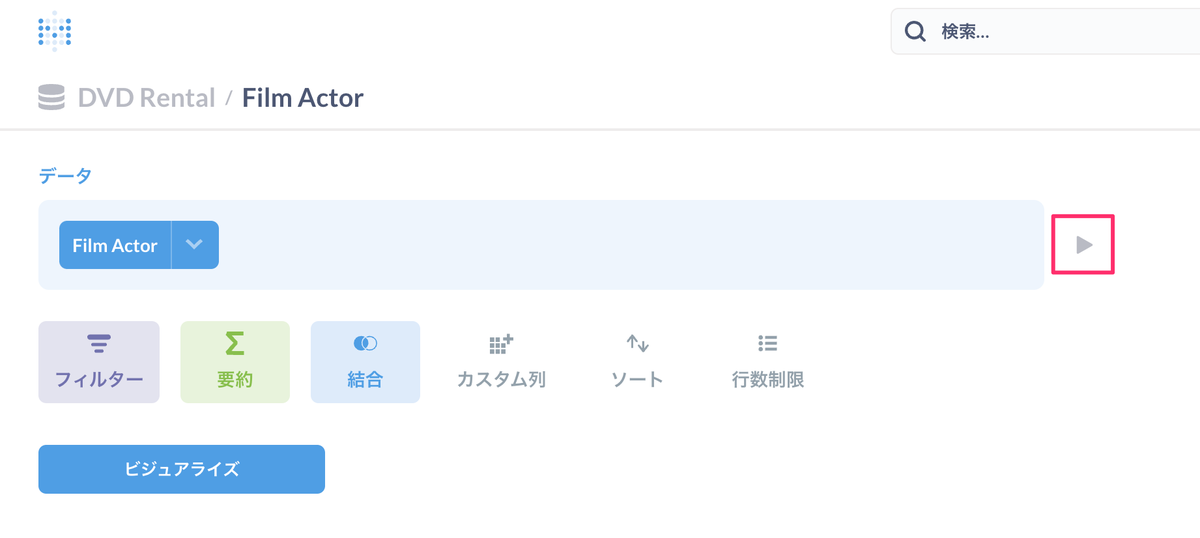
Film Actorテーブルの内容が表示されましたね。再生ボタンのようなものをクリックするとこのようにプレビューが表示されます。まだ何も条件を設定していないので、選択したテーブルの内容がそのまま表示されているだけですね。あくまでもプレビューなので「✕」をクリックして消しておきます。

ではJOINしましょう。「結合」をクリックします。
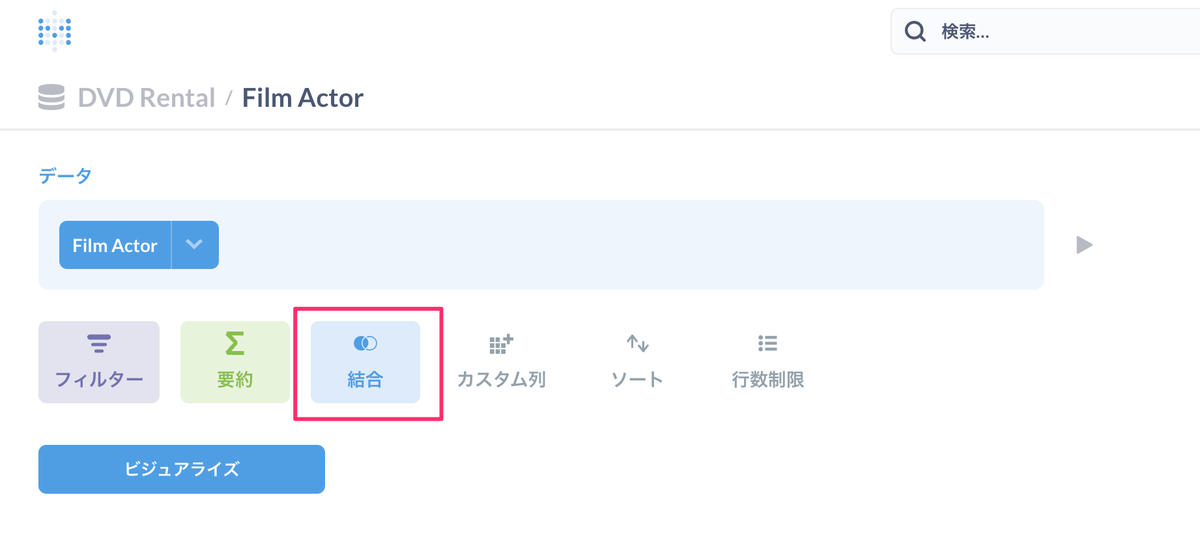
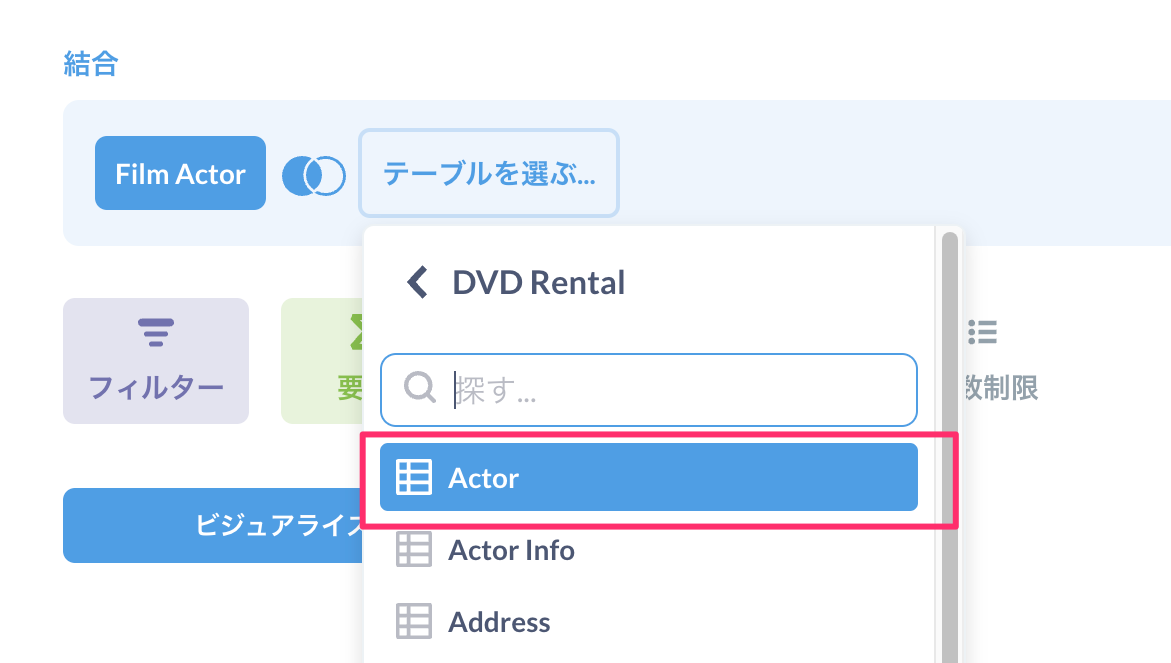
Film ActorテーブルとJOINするテーブルを選択します。まずはActorテーブル。
次に、テーブル間で結合させるカラムの組み合わせを選択するのですが、Film ActorテーブルとActorテーブルの各Actor IDがもう選択されていますよね。Metabaseではこのあたりもある程度類推して設定してくれるようです。もちろん自分で個別に設定することも出来ます。プレビューしてみましょう。
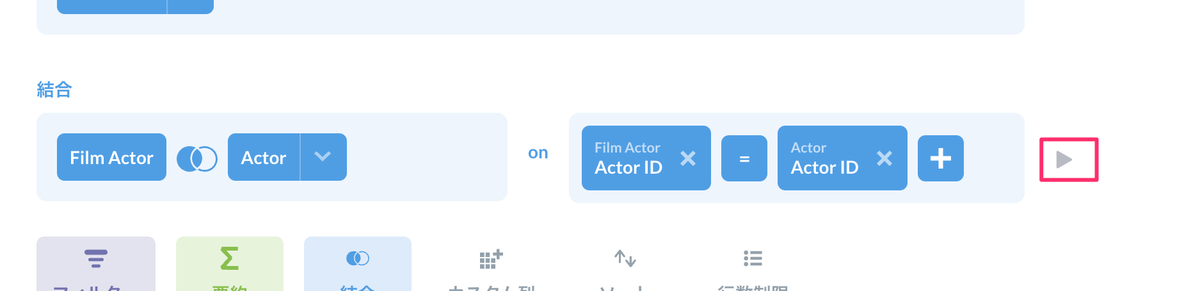
結合されたテーブルが表示されていますね。
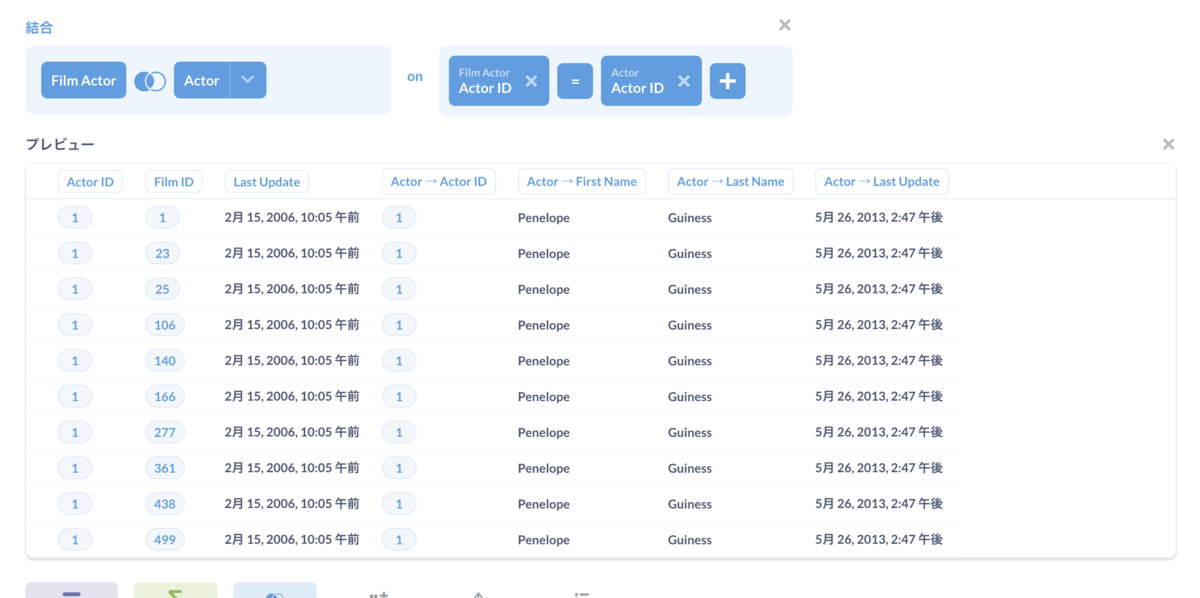
JOINで重複している項目がありますね。これを表示しないようにも出来ます。開始となるテーブル側でもJOINさせたテーブル側でもどちらでも設定できますが、今回は結合させたテーブル側のActor IDを表示しないようにしてみましょう。「結合」のところにあるActorテーブルの右の下向きのアイコンをクリックします。
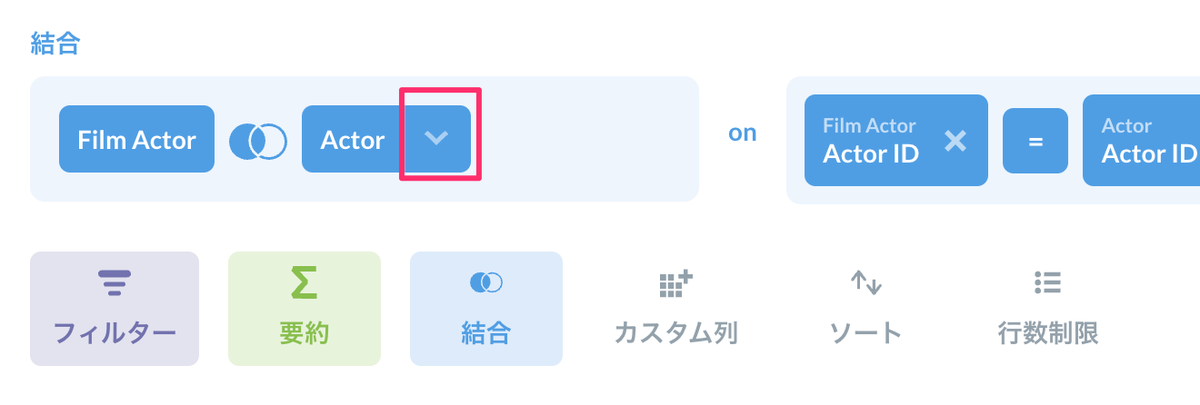
ここで表示しない項目のチェックを外せばOKです。
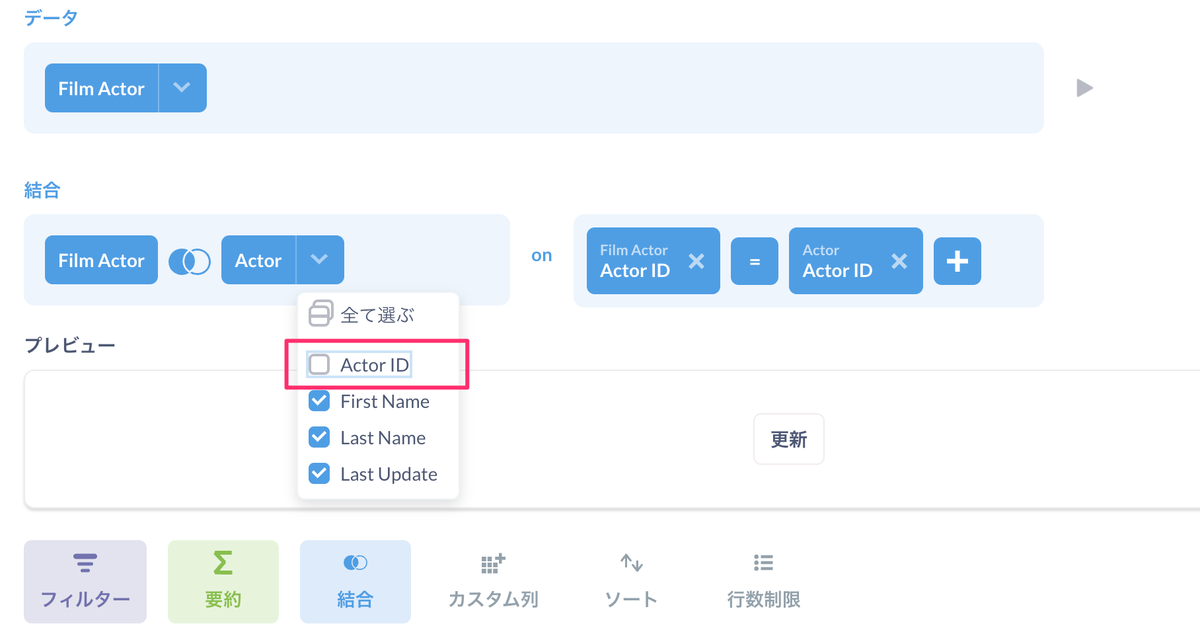
プレビューが消えましたね。「更新」をクリックしてみましょう。
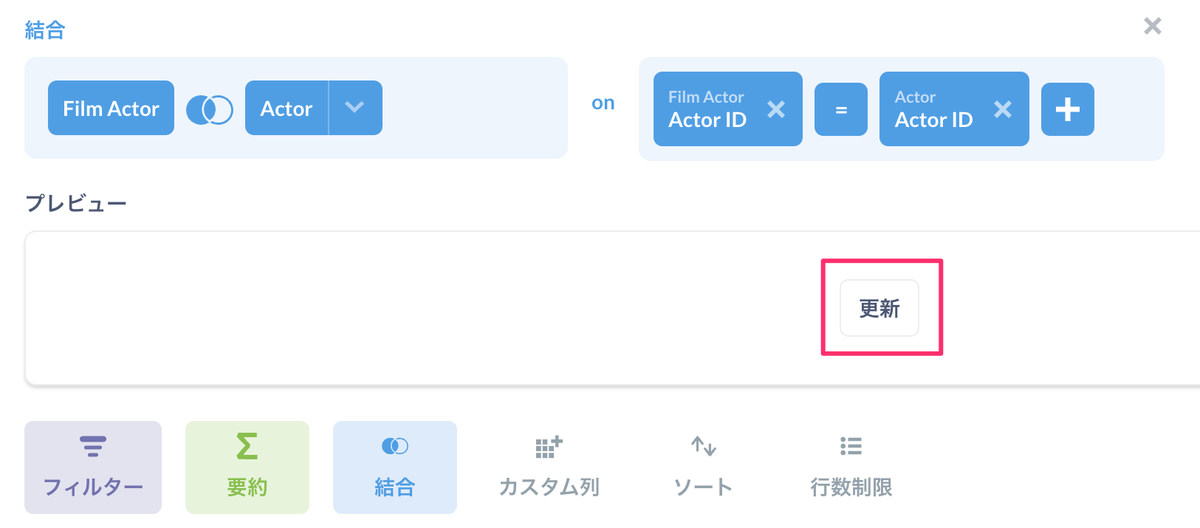
チェックを外した項目が消えていますね。

また、JOINの種類を変更することも出来ます。Film ActorテーブルとActorテーブルが結合されているところのアイコンをクリックします。
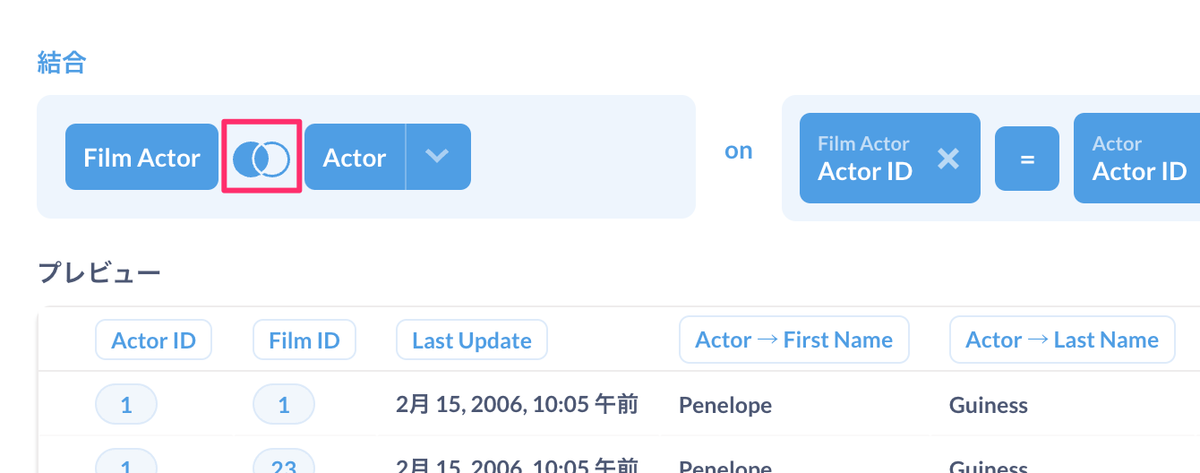
現在はLEFT JOINになっていますが、これをINNER JOINにしてみましょう。
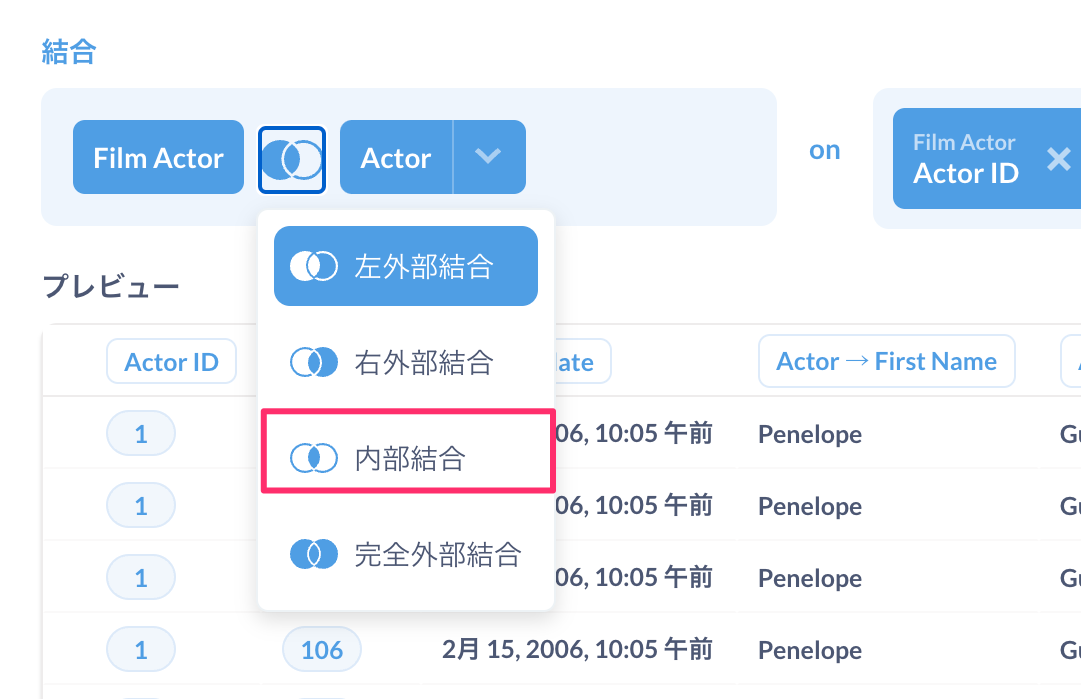
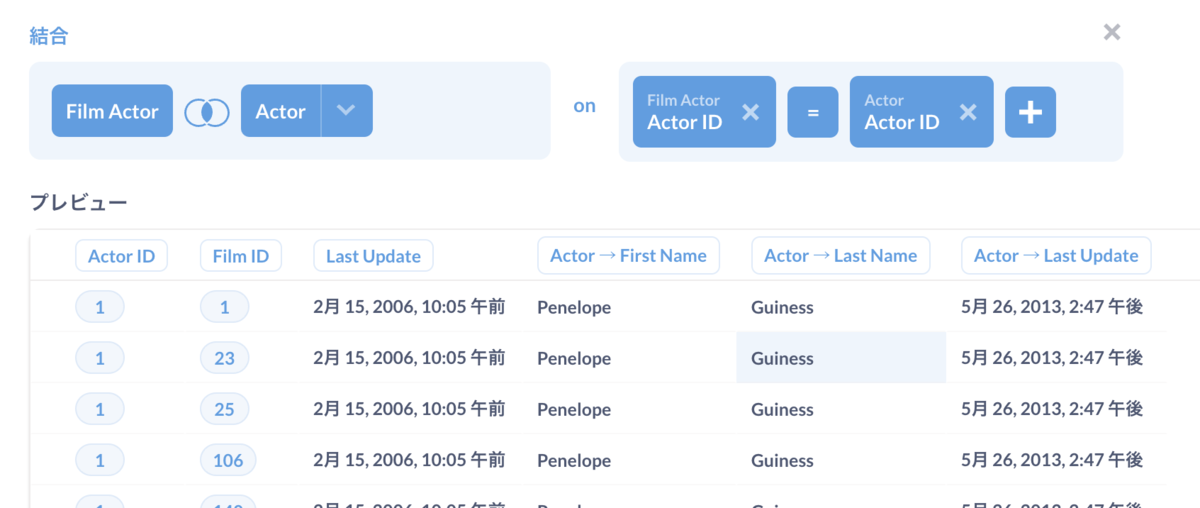
変更するとアイコンが変わっているのがわかりますね。変更後のプレビューを更新しましょう。Actor IDはActorテーブルでユニークなのであまり意味はないですけどね。
このようにして結合していけばOKです。ということで、再度「結合」からFilmテーブルも結合します。わかりやすくするためにいろいろ非表示にしました。こんな感じになります。
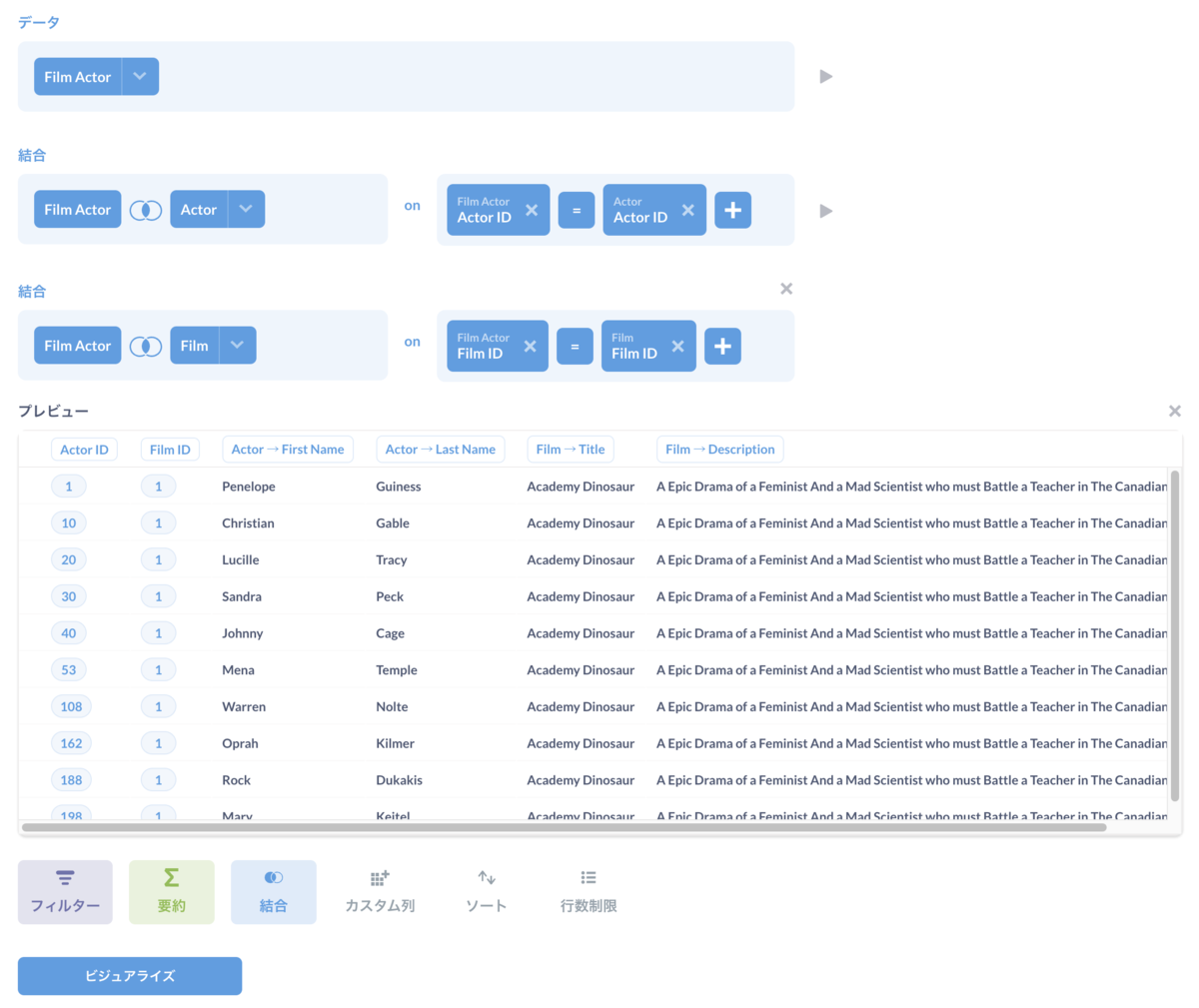
次に特定の俳優で絞り込んでみましょう。「フィルター」をクリックします。
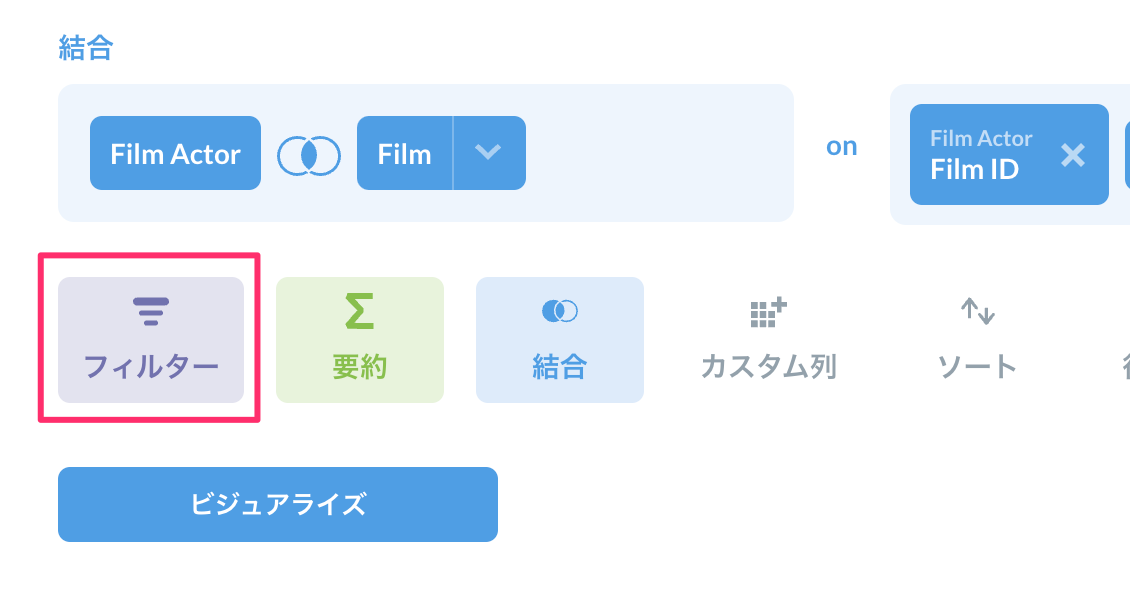
First Nameが"Nick"なレコードを絞り込みたいので、JOINされているActorテーブルのFirst Nameを選択します。

First Nameカラムのすべての値が表示されていますので"Nick"を選択すればOKです。絞り込み検索もできますね。「フィルターを追加する」をクリックします。

プレビューしてみるとこんな感じで絞り込みが出来ていますね。

ではプレビューではなく最終形としてビジュアライズしましょう。「ビジュアライズ」をクリックします。
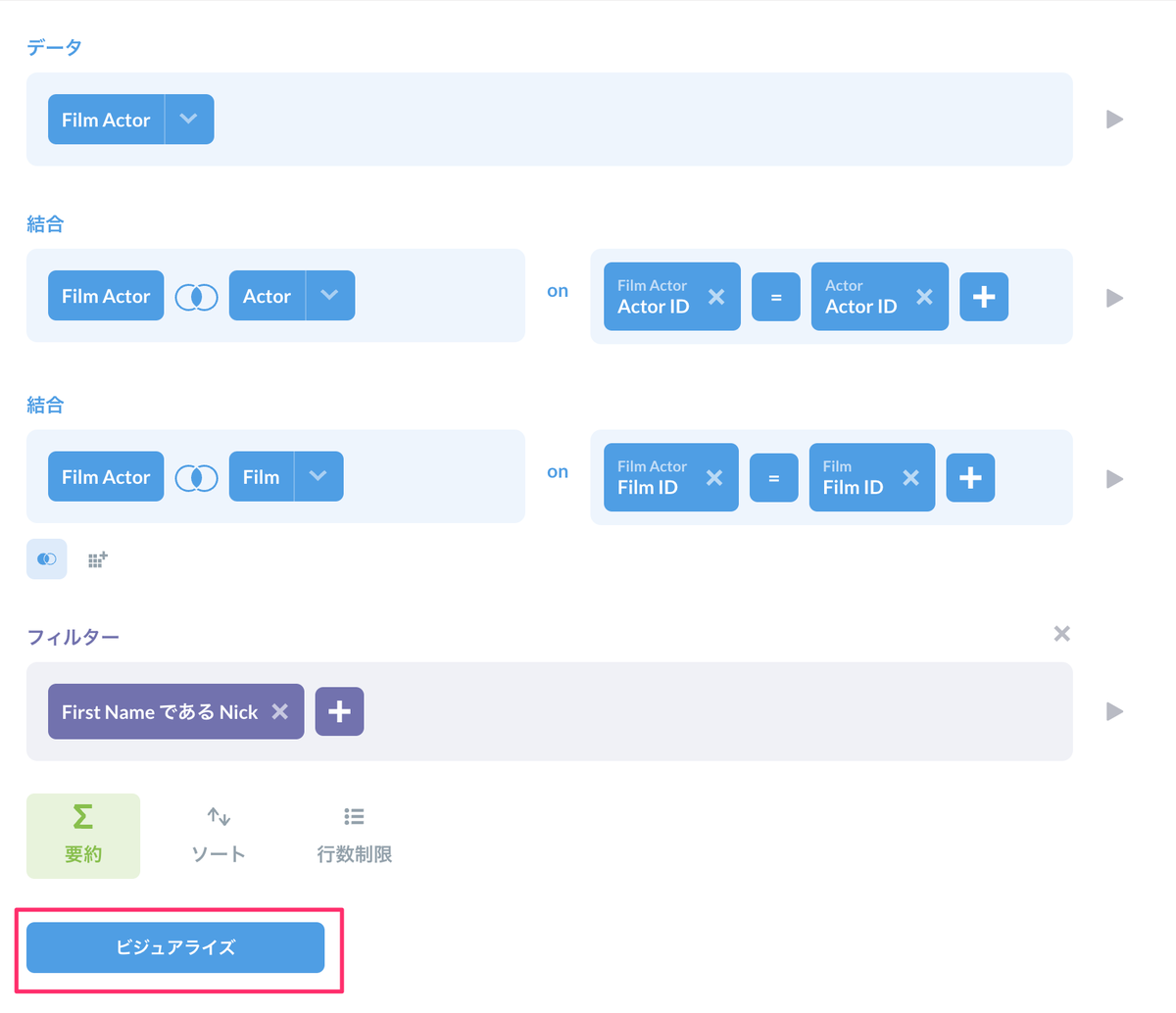
はい、これで表のビジュアルができましたね。

とはいえプレビューとはそんなに変わらないですよね。少し表をカスタマイズしましょう。下のほうにある「設定」をクリックします。
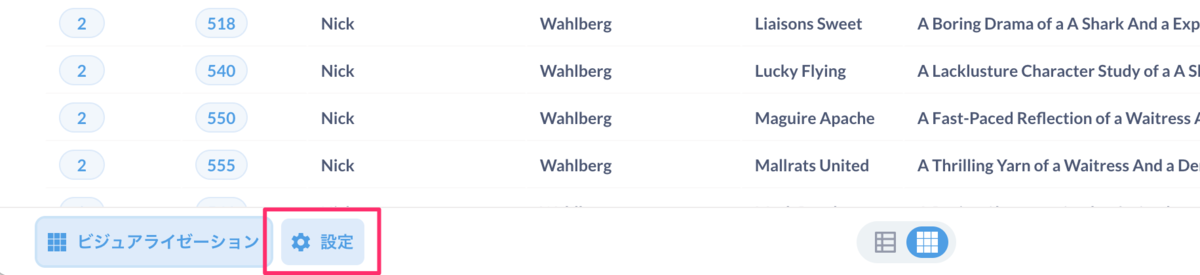
左に各カラムが表示されていますね。ここで順番を変えたり、表示・非常時を切り替えたり、また表示上のカラム名を変更することが出来ます。

少しいじってみました。カラムの名前が変わっていて、あといくつか非表示になっているのがわかりますでしょうか。

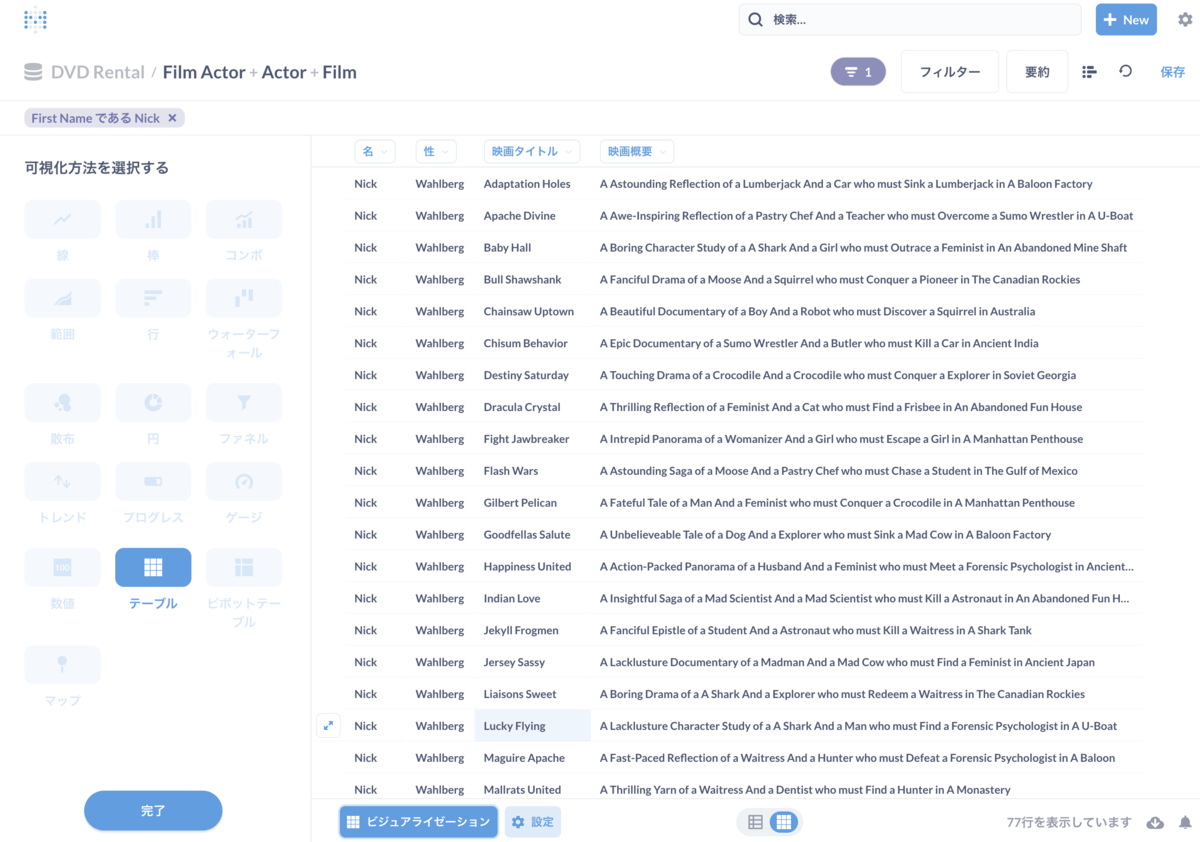
あと下の「設定」の横にある「ビジュアライゼーション」をクリックすると、他の表示形式に切り替えることが出来ます。ただし切り替えれるのはデータをどのように抽出したか?に依ります。今回のデータだと表敬式以外を選択するためにはいろいろ設定が足りないので選択できないということですね。
では最後にこれを保存していつでも呼び出せるようにしましょう。右の上の「保存」をクリックします。

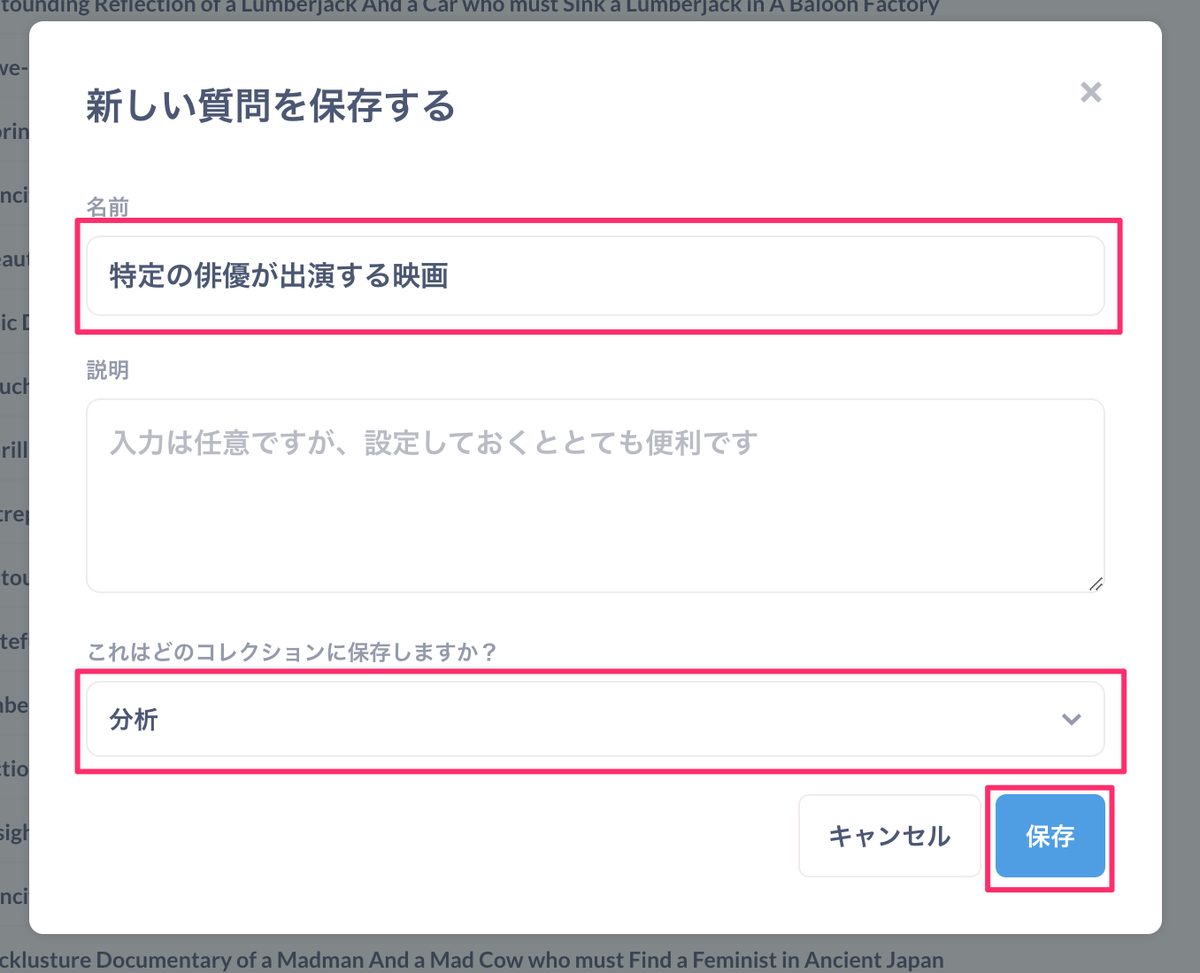
呼び出すときにわかりやすい質問の「名前」を設定します。説明は必要なら入力します。コレクションはフォルダのようなものですね。ここではデフォルトの「分析」にしておきます。最後に「保存」をクリック。
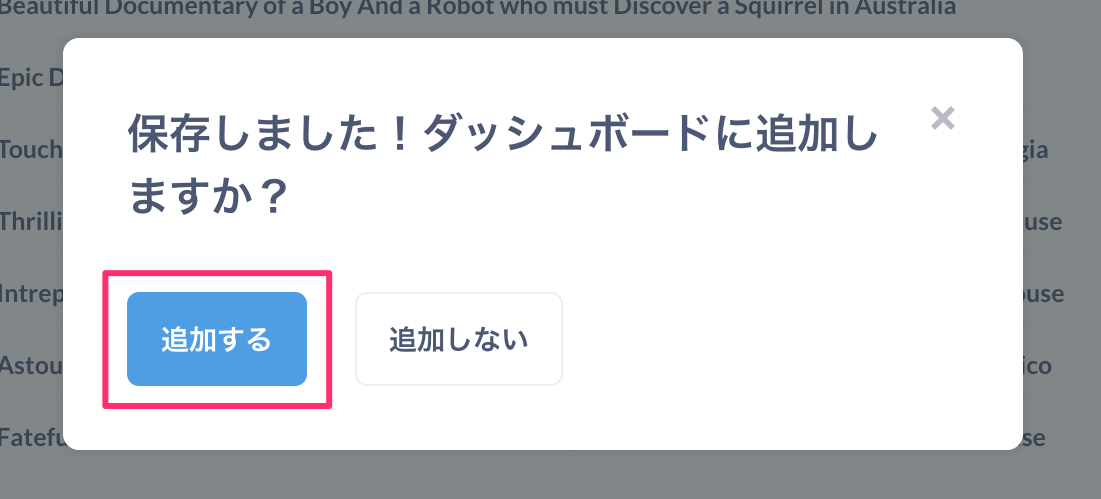
質問が保存されると、ダッシュボードに追加するかを聞いてきます。ダッシュボードは質問で作成した複数のビジュアルをひとまとめにして見やすくするためのものですね。せっかくなので追加してみましょう。「追加する」をクリックします。
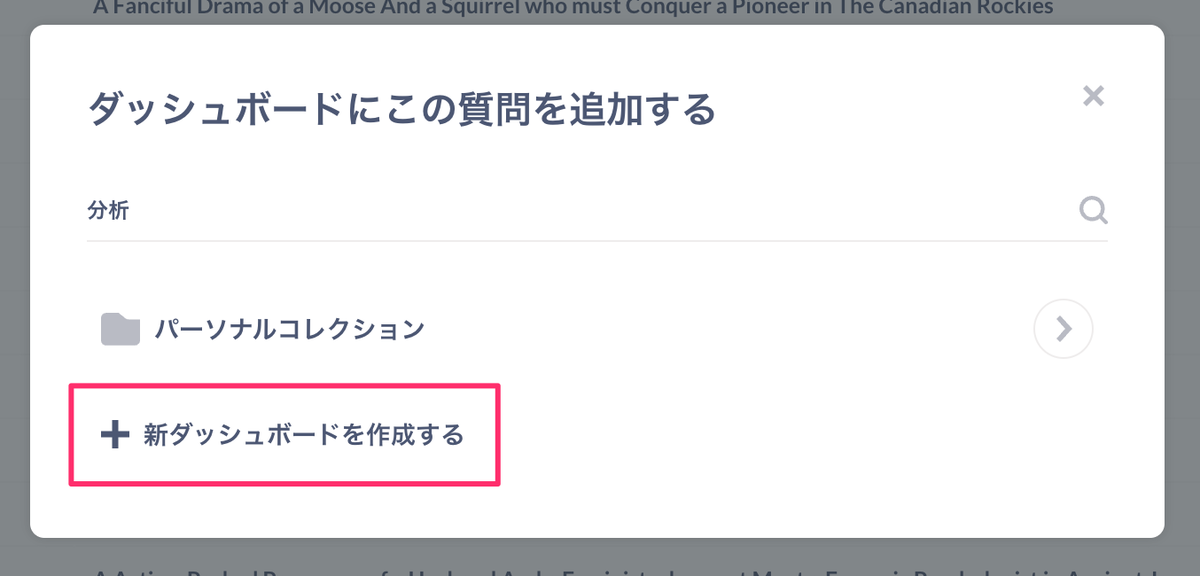
どのダッシュボードに質問のビジュアルを追加するかを聞いてきます。今回は新しく作ってみましょう。「新ダッシュボードを作成する」をクリック。
ダッシュボードの名前と保存先のコレクションを選択します。適当に設定して「作成する」をクリックします。

ダッシュボードが表示されます。作成した質問のビジュアルの場所や表示サイズなどを変更できます。質問を作成してビジュアル化、ダッシュボードに追加していくことで、ひと目でデータを確認することができるというわけですね。
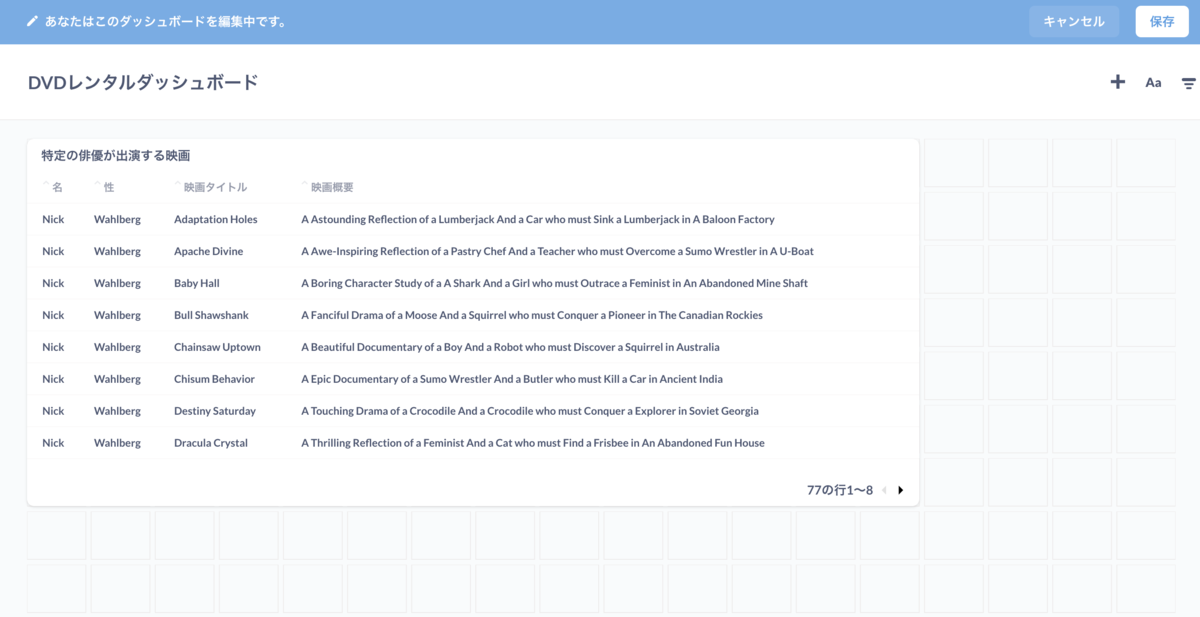
最後に保存を忘れず。
保存した質問やダッシュボードはトップページからコレクションをたどるといつでも参照・編集できます。元のデータを更新したり、質問を編集すれば、ダッシュボード内の表示も自動で変わります。

とりあえず今日はここまで。次回は別のお題もやりつつ、ダッシュボード上で条件を選択しやすくしたり、他のビジュアライズについても試してみたいと思います。