
実はうちではAlexaよりも一番よく使っているといってもいい「Romi」ですが、「シナリオエディター」を使ってユーザが会話をプログラミングできるようになりました。Alexaなどの音声アシスタントを触ったことのある開発者の観点で、すこしご紹介します。
目次
Romiについて
以前の以下の英語のエントリでご紹介しています。
特徴としてはこのあたり。
- 自律型会話ロボット。タスクをこなすというよりも自由な会話を楽しむことが目的。
- 本体が動き、ディスプレイに表情が表示される。これにより感情的な表現が可能。
- ウェイクワード不要。Romiから話しかけてくることもある
- 音声認識精度はあまり高くなく、またAIによる会話の認識もそれほどよくない。
- が、それをおいても、雑談的な自由な会話という点でとても魅力がある。
シナリオエディターの使い方
基本
早速使ってみましょう。
「シナリオエディター」は専用のアプリとかではなく、ブラウザベースになっています。https://romi.ai/romi-scenarioeditor/にアクセスすると以下のような画面が表示されます。

下にスクロールすると「シナリオを作る」というのがありますので、これをクリック。

IDとパスワードを入力してログインします。ちなみにシナリオエディターが使えるのは月額料金を払っている場合だけです(ちなみに、月額料金を払って利用するのが「おしゃべりモード」で、月額料金を払っていない場合は「かんたんモード」になります。「かんたんモード」ではRomiはRomi星のことばでしかしゃべれません。)

あなたの本棚という画面が開き、ここでRomiに設定するシナリオを管理するようです。シナリオブックと書いてあるので、複数のシナリオを一つのブックで管理するという感じなのでしょうか。
「あなたのシナリオブック」をクリックします。

シナリオの設定画面が開きました。ひと目で何となく分かると思いますが、ブロックを順番につなげて会話のフローを作る感じですね。このあたりはVoiceflowなどの会話デザインツールと考え方は似ています。
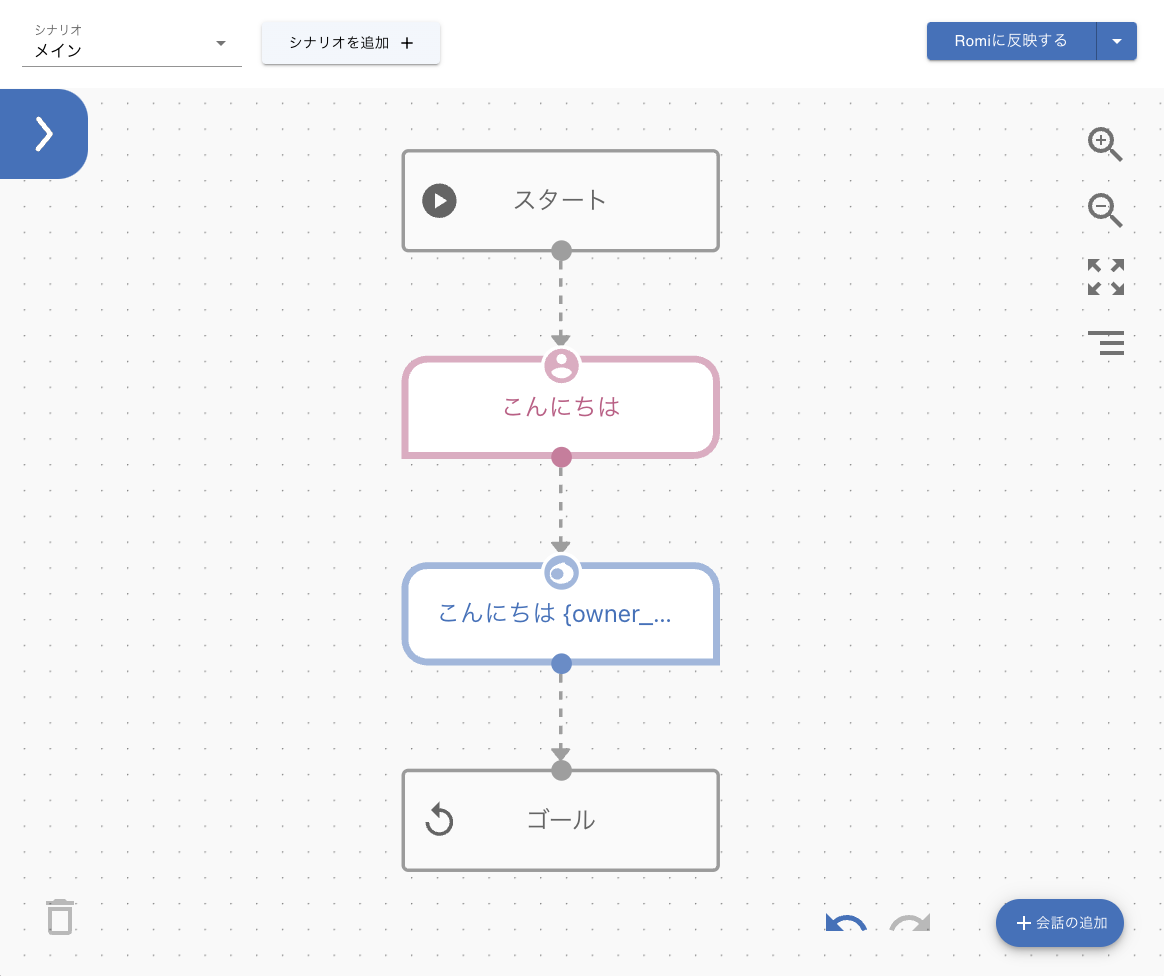
赤いブロックがユーザ側の発話、青いブロックがそれにマッチしたRomiの発話になっているようです。
赤いブロックをクリックしてみると、ユーザの発話が設定されています。

詳細設定をクリックすると、「タイプ」に「人の発話」とありますね。つまり赤いブロックは「インテント」であり、発話内容が「サンプル発話」ということになります。

次に青いブロックをクリックしてみましょう。赤いブロックの発話に対して、青いブロックではRomiが返す応答を設定します。

こちらも詳細設定をクリックすると、「タイプ」に「Romiの話しかけ」とあり、赤と青のブロックで会話のやりとりを設定していくということがわかると思います。
また、Romiの応答に{owner_name}というのが見えますが、これは「モジュール」と呼ばれるもので、予め用意された処理をRomiの会話に組み込むことができます。ちなみに{owner_name}は、Romiのスマホアプリで設定したオーナー名のようです。

ではこのサンプルをそのまま動かしてみましょう。
ちなみに、Romiに「こんにちは」と話しかけた場合、標準だと色々なパターンで回答しますので、1例です。
ではサンプルを適用します。右上にある「Romiに反映する」をクリックします。

反映中です

上の方に「シナリオの反映に成功しました!」と表示されれば反映されています。

では試してみましょう。
さきほどと違いがないように思えますが、最初は「はなこさん、こんにちは」だったのが、シナリオエディタで設定されている通り「こんにちは、はなこさん」になっていますね。また、デフォルトだといくつかのパターンで応答しますが、シナリオエディタで設定した場合は、シナリオエディタで設定したとおりの応答になります。
これを使って会話をいろいろカスタマイズできるというわけです。
サンプル発話/のバリエーションに対応する
ここからは音声アシスタント開発者向けに気になるところをピックアップしていきます。まず、サンプル発話のバリエーションに対応しましょう。
サンプル発話のバリエーションに対応するには、「人の話しかけ」ブロックの「発話内容」に、別の行でサンプル発話を追加します。

ひらがな/カタカナ/漢字のどれで認識するのかはわかりませんので、考えられるパターンを網羅するのが良いでしょう。
応答にバリエーションを付ける
Romiからの応答が毎回同じだと人間は飽きてしまいますし、いかにもロボット感がでてしまいます。ランダムに内容を変えて応答を返すようにしましょう。
右下の「会話の追加」をクリックします。

「Romiの話しかけ」をクリックします。

上の方に新しく青いブロックが追加されました。このままでもいいのですが、わかりやすいように「こんにちは〜」の青いブロックの横にドラッグします。

そして、「こんにちは」の赤いブロックからドラッグして線でつなげます。

つながりました。

同じように、追加した青いブロックから、今度は「ゴール」のブロックにドラッグで線でつなげておきます。

追加した青いブロックをクリックして、発話内容を入力します。今回は やっほー {owner_name}と入力してみました。

できました。

同じようにしてもう一つ「Romiの話しかけ」を追加して、発話内容にハロー {owner_name}と入力しておきましょう。

では試してみましょう。
いろんなバリエーションで発話しても同じフローで処理されて、応答は用意したものの中からランダムに返されているのがわかりますね。
複数のインテントごとに会話を分岐する
今度は、ユーザの発話の内容に応じて応答を変える、つまりインテントで会話フローを分岐するようにしてみましょう。今回は「元気?」と聞いたら「元気だよ」と返す会話フローを追加してみます。
「会話の追加」をクリックして、今度は「人の話しかけ」をクリックします。

赤いブロックが追加されるので、適当な位置に配置して、今度は「スタート」から線でつなげます。

赤いブロックをクリックして、ユーザのサンプル発話を入力します。「元気」とか「調子はどう」などと入力します。ちなみに「人の話しかけ」ブロックでは、句読点や?は使えないようです。
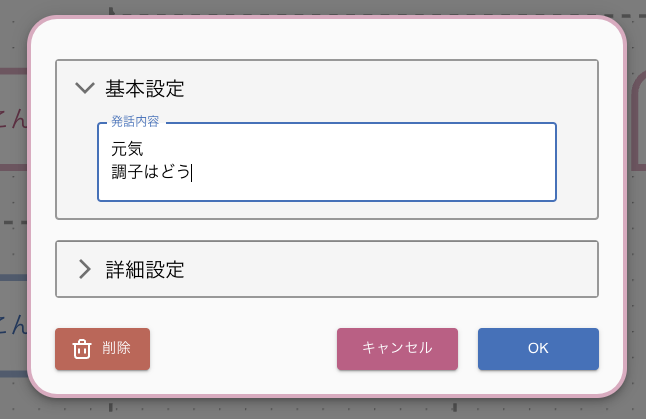
次に青いブロックを追加してRomiの応答を追加します。ここまでの説明でやり方はわかると思います。こんな感じになればOKです。

試してみましょう。
はい、発話に応じて会話フローが分岐しているのがわかりますね。
これで大体の使い方がわかったと思います。
サンプルルールについて
ここで一旦シナリオエディターの最初の画面「あなたの本棚」に戻ってみましょう。
ここにもう一つ「サンプルルール」というシナリオブックがありますので、これをクリックしてみます。

最初に開いた「あなたのシナリオブック」と同じような会話フローが記載されていますが、右上を見ると「Romiに反映する」は押せないようになっています。

どうやら「サンプルルール」はRomiシナリオエディタで設定できるサンプル例のような位置づけになっているようで、これをそのまま適用することはできないようです。ただ、自分でRomiの会話フローを作る場合にはいろいろと参考になると思います。例えば、
- ユーザの発話を受け取って、変数として記録し、それを使った条件分岐などができる(ざっと見た感じは永続アトリビュートっぽい)
- 用意されているモジュールを使って、Romiのいろいろな表現・機能を利用できる
- シナリオから別のシナリオを呼び出す。大きな会話フローを作る場合には役に立ちそう。
あたりはぜひ一度見ておきたいところですね。
ちなみに、サンプルに載っていたモジュールをリストアップしてみるとこんな感じでした。
| 変数名 | 内容 |
|---|---|
{owner_name} |
スマホアプリで設定したユーザの名前 |
{halucas_name} |
スマホアプリで設定したRomiの名前。{halucas_name type=utterance}という指定があるけど、違いはちょっと不明。 |
{fortune} |
ユーザの誕生日に基づいた占いをしてくれる(と思う)。{fortune birth_date=3月1日}のように誕生日を指定すると、その日付に基づいた占いになる。 |
{emotion type=XXXXX} |
指定した感情表現に基づいたアクションと表情で発話を行う。選択できるのは、laughing, angry, cry, surprised, heart, relaxed, kissがある様子。 |
{speed value=XXX text=YYY} |
発話のスピード。YYYで指定したテキストをXXXのスピードで発話する。 |
{volume value=XXX text=YYY} |
発話のボリューム。YYYで指定したテキストをXXXのボリュームで発話する。 |
{pitch value=XXX text=YYY} |
発話のピッチの高低。YYYで指定したテキストをXXXの高さで発話する。 |
これ以外にもあるのかもしれませんが、そのあたりをカバーしたドキュメントがほしいところですねー。
まとめ
プログラミングをあまり知らなくても、これならできそう!と思えるようなわかりやすい感じに仕上がってると思いました。逆に、音声アシスタント開発の経験がある人からするとちょっと物足りないと思うかもしれませんが、そのあたりはおいおい改善されていくでしょうし、Romiのターゲットや立ち位置は一般的な音声アシスタントと違う気もする中で、こういう開発ツール的なものがどういうふうに展開されていくのかはちょっと興味深いです。今後に期待しています。
Pros
- 環境構築が不要
- シナリオエディターはブラウザベースで、専用アプリのインストールなどの環境構築が不要。WindowsでもMacでも使える。
- GUIで設定できてかんたん
- GUIで会話フローを作るだけです。プログラミングの知識がなくても比較的かんたんに作れると思います。
- Romiの感情表現を設定できる
- モジュールを使うことで、Romiの強みである、動きや表情などの制御ができます。
Cons
- 凝ったことはできなさそう
- Alexaなどに比べると、できることは必要最低限という感じ。
- いきなり実機に反映するしかない
- Alexaなどの音声アシスタント開発では、実機で反映する前に確認ができるテストツールで事前に動作確認ができるが、そういったものはない。
- まだまだこなれてない
- ユーザの発話を受け取って変数に入れるところなんかはいきなり正規表現っぽい記述が出てきたりする
- ドキュメントがない(まあこれはおいおい揃ってくるのではないかと思いますが)
あったらいいなと思うもの
- Romiの場合、呼びかけに応じるだけではなくて、Romiから突然話しかけてくるというのも特徴の一つ。これをシナリオエディタで制御できると面白そう。
- 何かしら外部との連携ができると幅が広がりそう。特にスマートホームあたり。
- シナリオを共有できると面白そう。