
VoiceflowのCapture Stepが新しくなりましたのでご紹介します。
目次
これまでのCapture Step
Voiceflowには、ユーザからの発話を受け取って変数に入れるためのステップは主に以下の2つになります。
- Capture Step
- Choice Step
Choice Stepは、インテントごとに分岐させるためのステップです。そして、インテントごとにサンプル発話を用意しておいて、そこに含まれるスロットを変数として受け取ります。どのインテントにマッチしなかった場合の処理や、複数のスロットを受けるためのマルチターンの設定なんかもできて、とても柔軟です。ユーザからの発話の受け取とりはChoice Stepを使うのが基本になると思います。

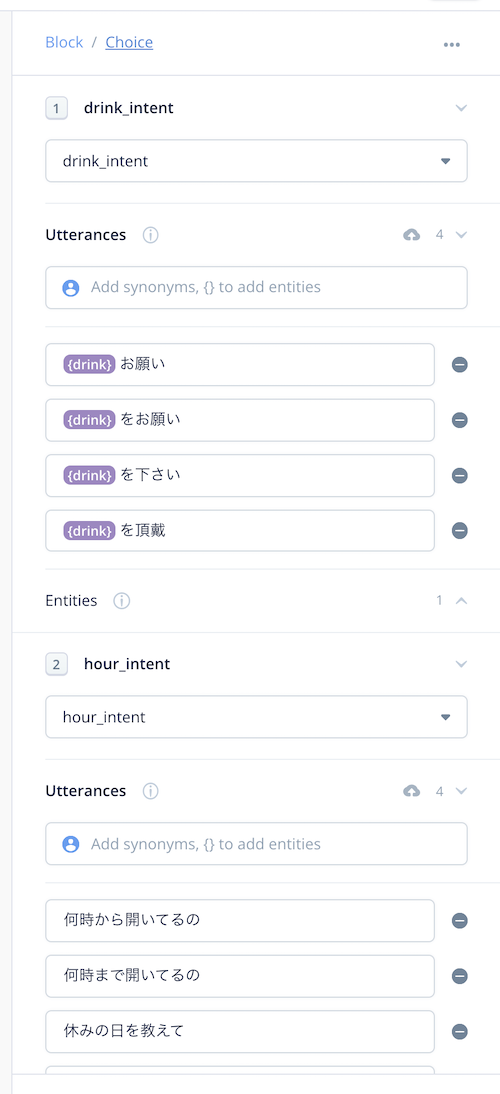
これに対しCapture Stepは、ダイレクトにスロットだけを受け取りたい場合に使います。

Choice Stepに比べるととてもシンプルでかんたんそうに見えますよね。特にVoiceflowを触り始めたばかりだと、インテントやサンプル発話、スロットの概念もまだ難しいでしょうし、Choice Stepよりもこちらのほうがわかりやすく感じると思います。ただ、色々と問題がありました。
これまでのChoice Stepの問題点
これまでのChoice Stepが想定しているのは、以下のような会話フローになります。
ご注文は何にしますか?
コーヒー
コーヒーですね。ご注文ありがとうございました。
以下の通り問題なく動作します。

では以下のような発話の場合にどうなるか見てみましょう。
コーヒーをください
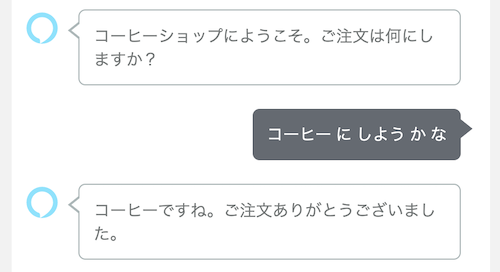
コーヒーにしようかな

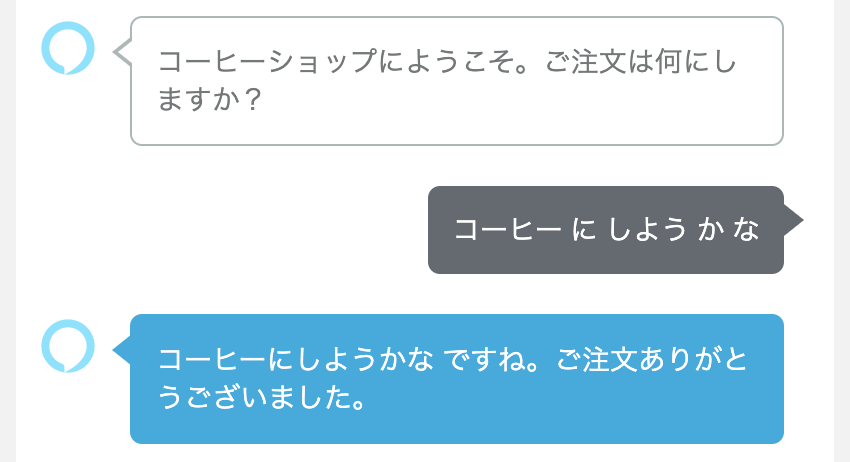
コーヒーの前後も含めた形で取れてしまっていますね。Choice Stepではスロット単体の回答を期待しています。上記のような「人間らしい」発話からスロットだけを取り出すようなことができません。
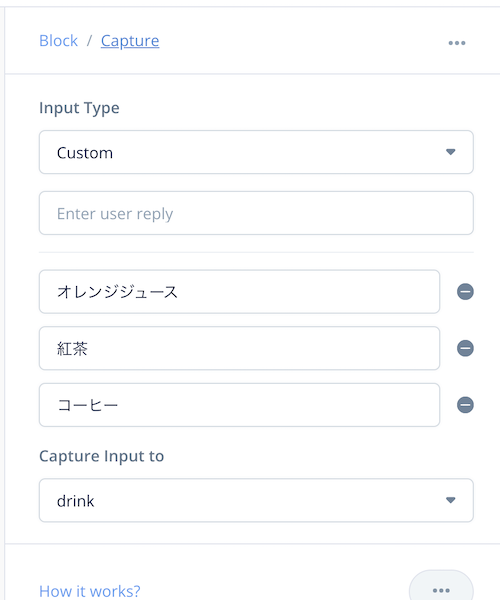
ただ、上記の例ではカスタムタイプを使っていて、スロット値のサンプルは3つしかありません。これはちょっと少なすぎてうまく認識できなかったという可能性もあるかもしれませんね。ビルトインのスロットタイプであれば、認識精度は上がるはずです。少し変えてみましょう。

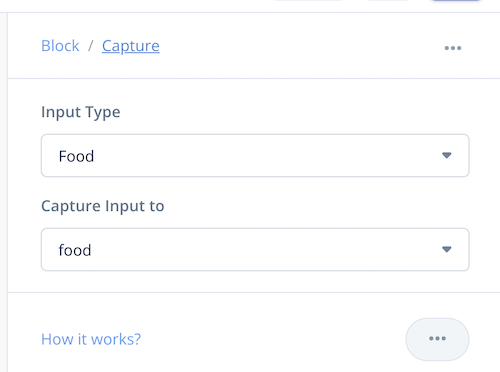
ビルトインスロットタイプに「飲み物」はありませんが、代わりに「食べ物」(AMAZON.Food)があります。これを使いましょう。レストランの注文という感じに変えてみました。さてどうなるでしょうか。
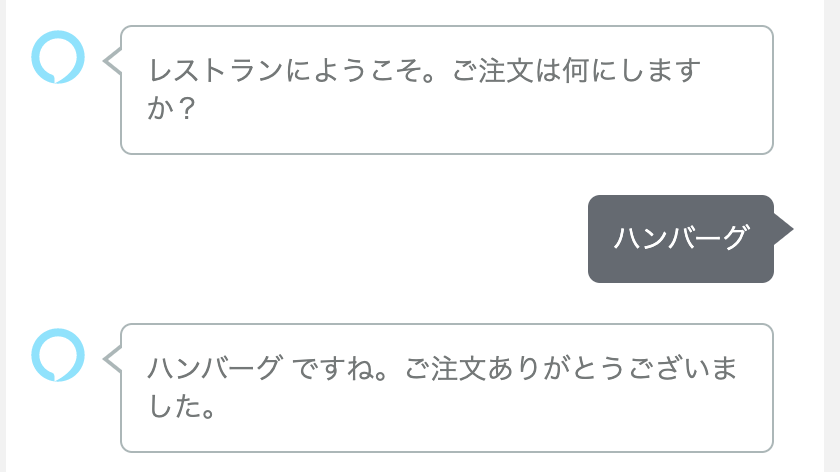
これはまあ当然として。
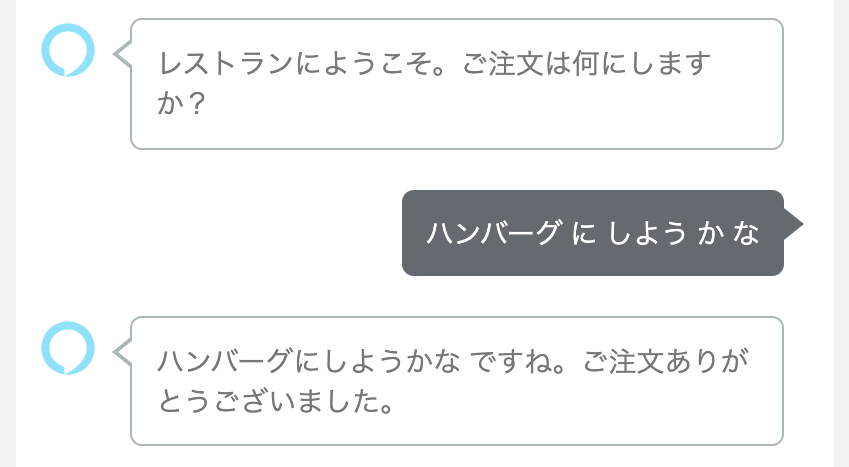
やっぱりダメですね・・・もっとひどいパターンだと・・・
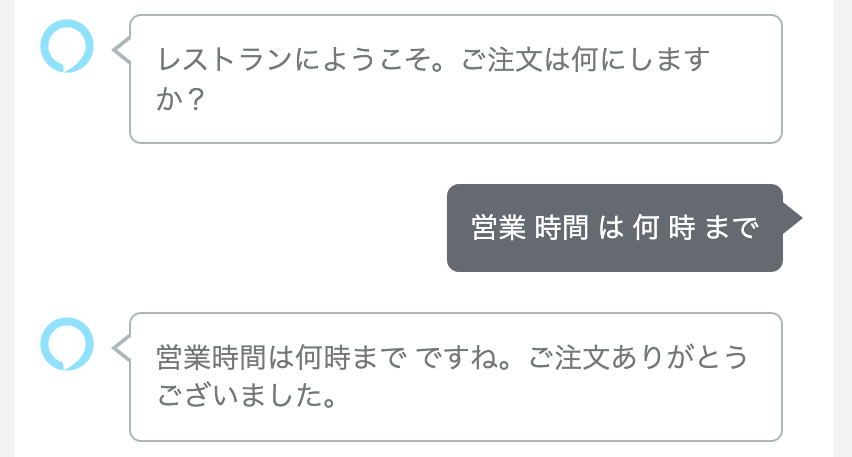
こうなります。全然インテリジェントな音声アシスタントじゃないですよね。
今回パッと再現できなかったのですが、もっと酷いケースになるとそもそも何も値が取れない(0という値で渡ってくる)というケースもあります。発話がスロットとして認識されないようなケースですね。こういったことを回避するには、Captureで受け取った値が正しいか?をチェックするというようなエラー処理を追加する必要がでてきます。
これに対して、Choice Stepを使う場合だと、
- サンプル発話とスロットをきちんと設定しておけば、スロット単体の値だけきちんと取れる
- スロットが取れない≒インテントにマッチしない、ということでNo Matchを使ったエラー処理もできる(とはいえ、値チェックはやったほうが良いと思います)
ができます。
つまり、Capture Stepは一見シンプルでかんたんそうに見えますが、実際には、人間の会話のような柔軟性がなく、想定外の発話に対してとても弱かったんです。遠回りでもChoice Stepを使うほうが良いわけです。
新しくなったCapture Step
とはいえ、簡単にできるのであればやっぱりそっちを使いたいですよね。ということで、新しくなったChoice Step、どういったところが改善されているのかを見てみましょう。
新しいCapture Stepは、以前とちょっと場所が変わってUser Inputの下にあります。アイコンも変わっています。

これまでのChoice Blockと置き換えてみます。パッと見でわかるようにスロット値が正しく取れない(スロットとして認識されない)場合のNo Matchが追加されています。これは助かりますね。

ステップの設定を見てみましょう。先ほどお伝えしたとおりNo Matchのメニューが追加されていますね。ここはChoice Stepと同じなので割愛します。上のフォームのところにスロット名を入力すれば良さそうですね。
入力しようとすると「Entire user reply」というのが表示されますが、これは後ほど。普通にスロット名を入力します。
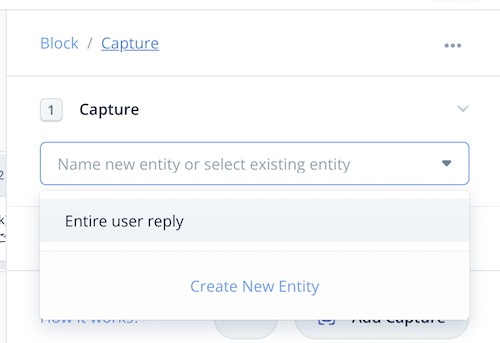
今回のサンプルでは"drink"としました。ENTERで確定させるか、"Create ..."をクリックします。

いつものスロットタイプの作成画面ですね。カスタムタイプでいくつかサンプル値をいれました。もちろんシノニムも使えます。
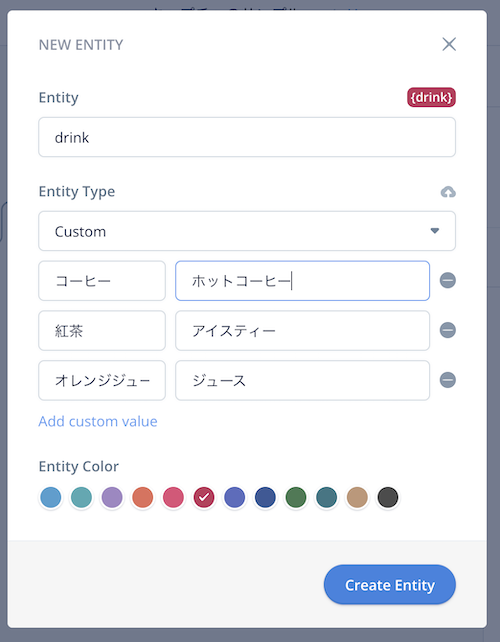
スロットタイプ作成後、ステップの設定画面に戻ってくると、新しい設定が増えていますね。
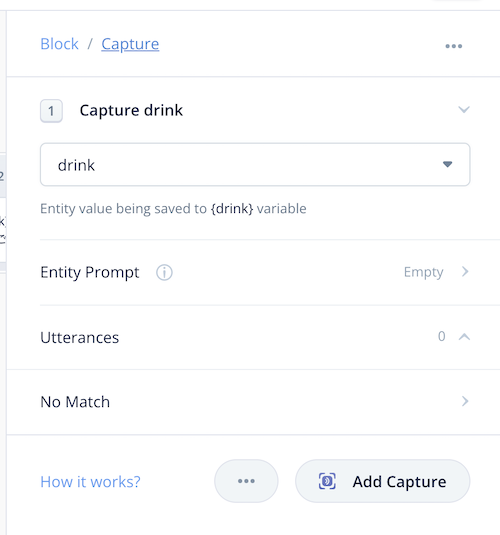
まずUtterancesですが、これがサンプル発話になります。上で書いたとおり、以前のChoice Stepではスロット単体の発話(「コーヒー」)しか想定できなかったのが、サンプル発話中のスロット(「コーヒーをください」)にも対応できるようになります。なお、スロット単体のサンプル発話は不要です(自動で追加されます。)

テストしてみるとちゃんと動いてるのがわかります。
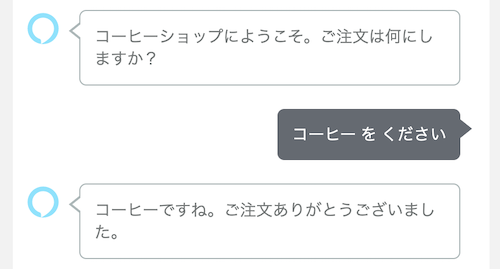
スロット単体ももちろんこれまで通り動きます。シノニムも問題ないですね。

設定画面に戻ります。スロットタイプを作成したあとにもう一つ新しい項目「Entity Prompt」がありますね。

Capture Stepの設定でもう一つ追加されているEntity Promptは、スロットが取得できなかった場合にユーザに発話を促すための発話を設定します。No Matchとの違いがわかりにくいですね。わかりやすくするために別のサンプルを用意しました。

名前を聞いて挨拶をするというサンプルです。Capture Stepの設定では、スロット「name」とそれを含んだサンプル発話を設定しています。スロット「name」はAMAZON.FirstNameを使っています。

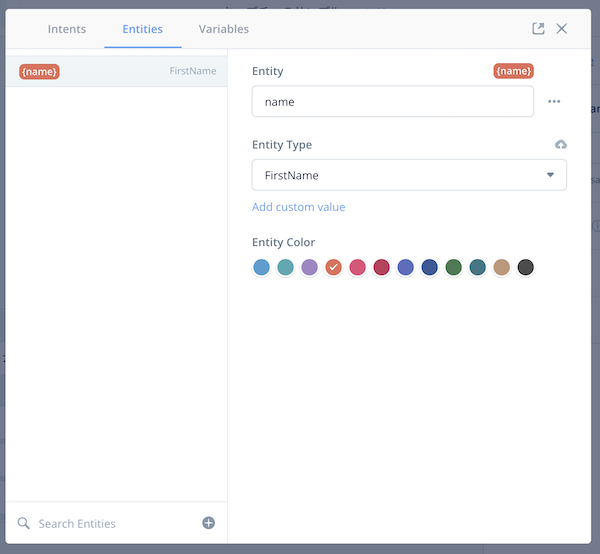
No Matchも設定してあります。
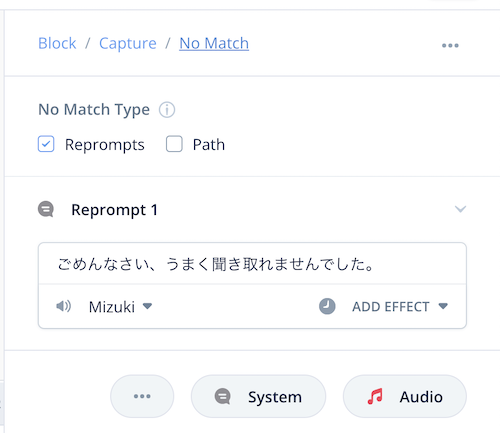
では、Entity Promptをこんな感じで設定しましょう。

試してみましょう。全然関係ないことを回答してみます。

サンプル発話にマッチしないということで、No Matchに設定した内容が発話されて、その後、Entity Promptの内容が発話されて、ユーザに発話のヒントを促しているわけですね。
ただ、これ別にNo Matchで設定しちゃえばよさそうですよね、わざわざ分ける必要はないようにも思えます。Entity Promptが生きるのは別のケースにあります。
以下をご覧ください。

そう、新しいCapture Stepでは、複数のスロットを取得することができるんですね。このケースでEntity Promptが役に立ちます。
では、名前に加えて、年齢を聞くようにしてみましょう。スロット名「age」を作りましょう。

スロットタイプはAMAZON.Numberですね。
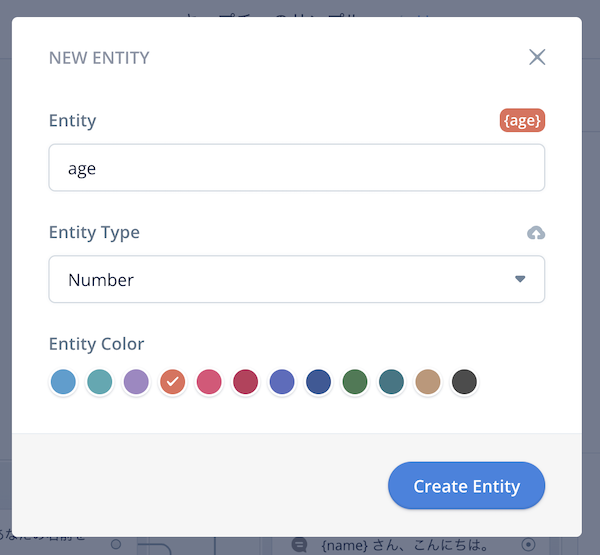
サンプル発話もこんな感じで。

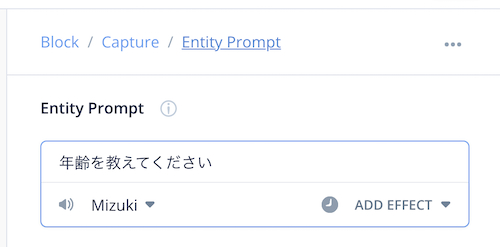
Entity Prromptで年齢を聞くように促します。
最後のSpeak Stepで年齢も答えるようにしておきます。
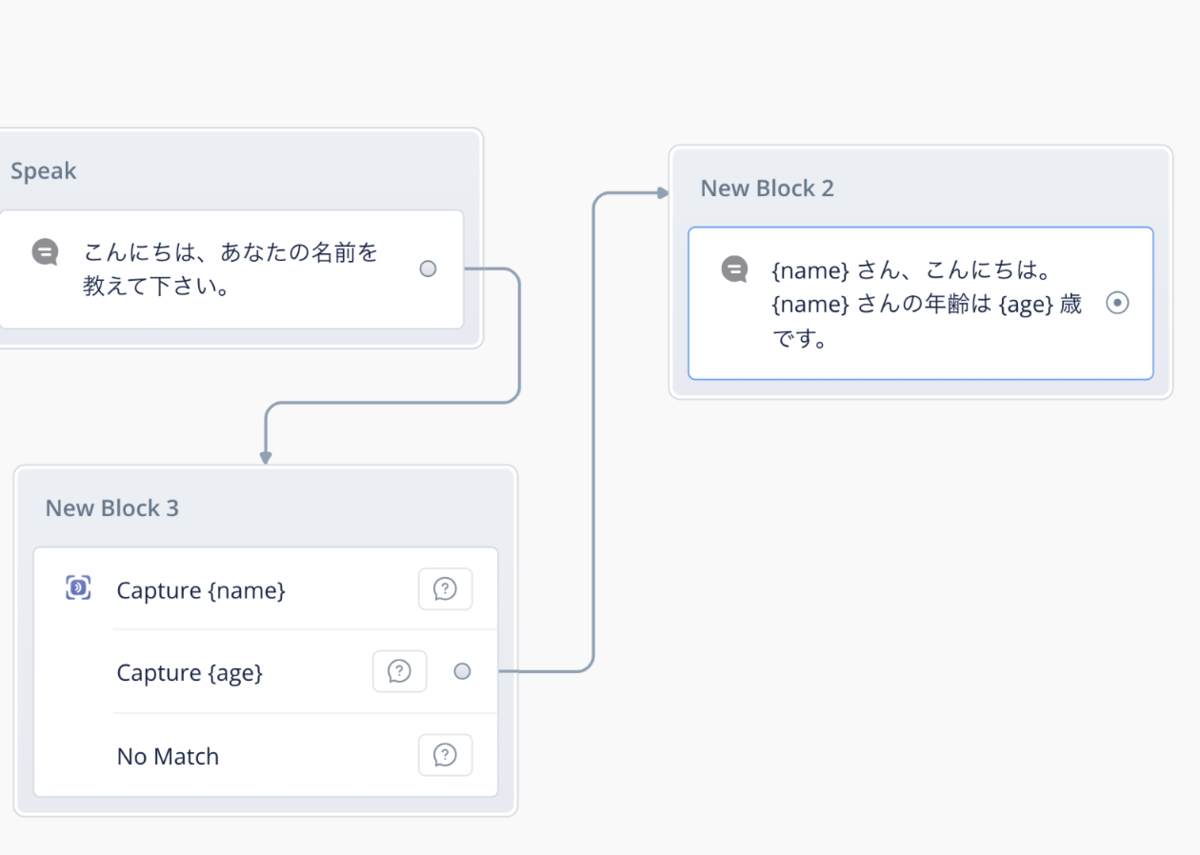
ではテストしてみましょう。

はい、それぞれのスロットが順番に聞かれるようになりましたね。
ただし、ここはいくつかおかしな動きもあります。全然関係ないことを答えるパターンも見てみましょう。
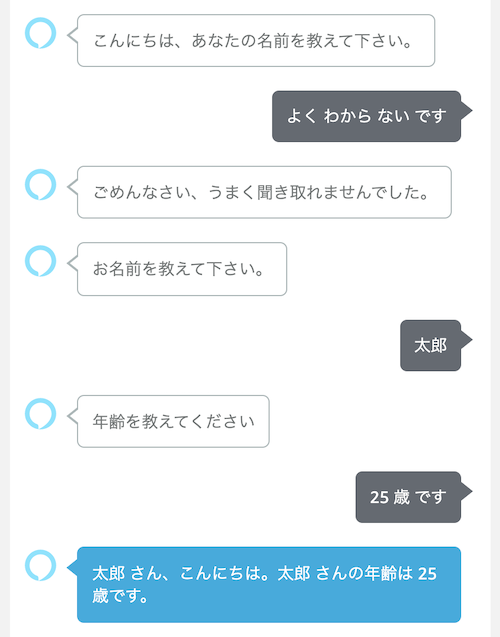
こんな感じで上手く言ってるように見えますね。もう一つ。
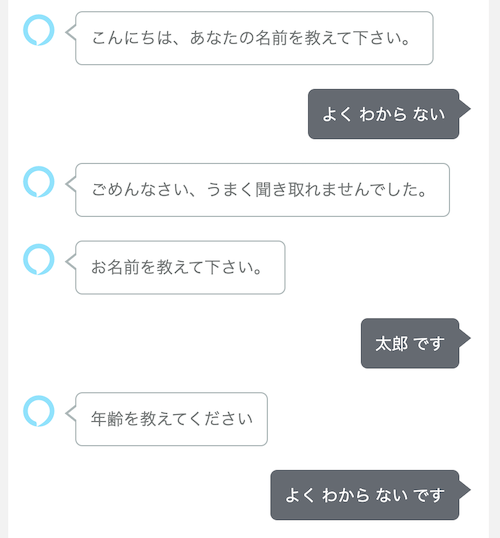
実はこれ最後の発話でスキルが終了してしまっています・・・
おそらくですが、Alexaの場合はダイアログモデルを使っていると思いますが、ダイアログモデルのスロット収集は2回失敗するとスキルが終了してしまうのでそのせいではないかと思います。
また、もう一つ。
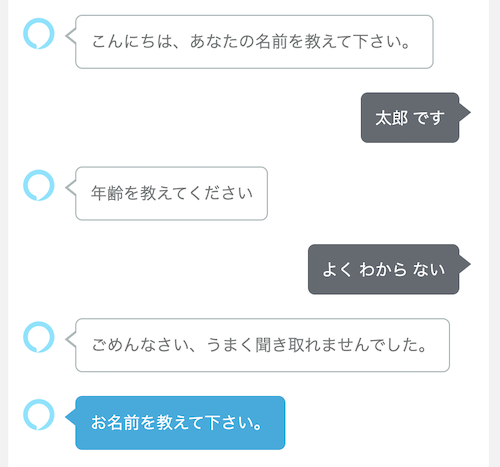
2回目の年齢スロット収集で失敗した場合、再度名前の確認からに戻ってしまいますね。。。
一回の発話で複数スロットを設定する方法もあるみたいですが、ちょっとまだ挙動を抑えきれていません。複数のスロットを確実に受け取りたい場合は、現状はChoice Step を使うほうが良いかもしれません。
このあたりはもう少し確認が必要かなと思いますが、少なくともサンプル発話に対応できるのとNo Matchが使えるようになっただけでも、かなり便利になっていると思います!
「Entire user reply」とは?
スロット名をつける際に選択できる「Entire user reply」についても見てみましょう。これはスロットではなくマルッとユーザの発話を取得することができます。
少しサンプルを変えてみましょう。いわゆる「オウム返し」です。
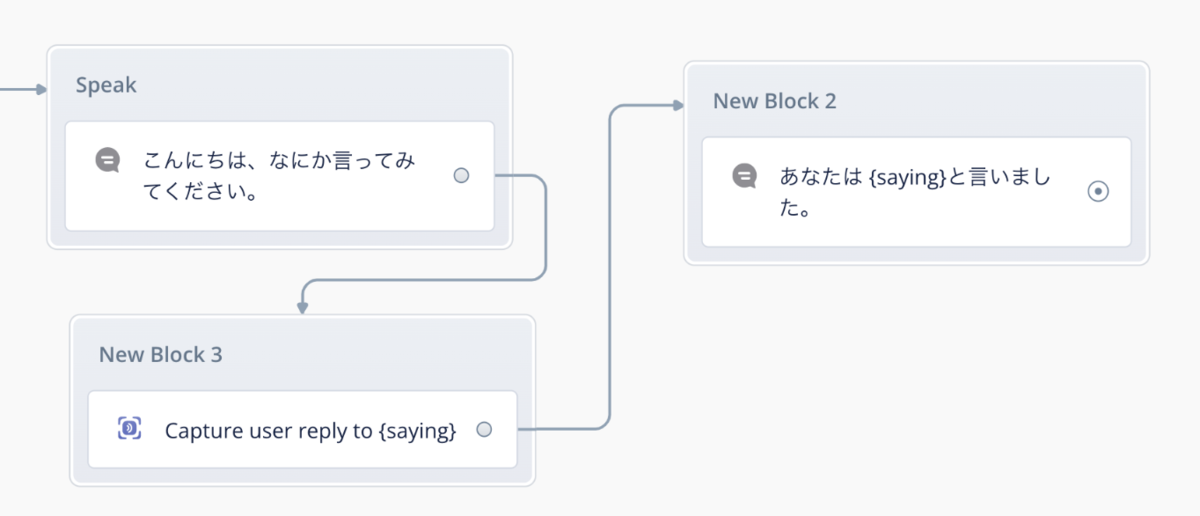
Capture Slotで「Entire user reply」を設定して、スロット名を指定します。
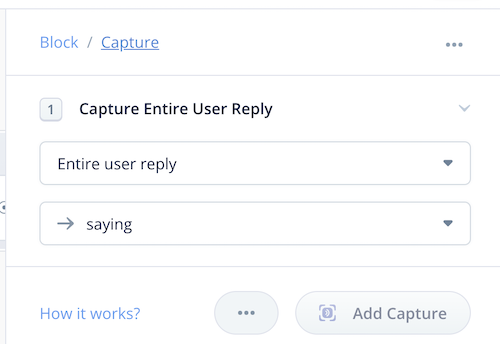
試してみましょう。
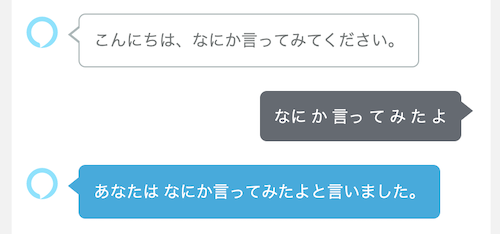
ちゃんと動いていますね。Alexa開発者コンソールを見ると、SearchQueryで設定されているのがわかりますね。
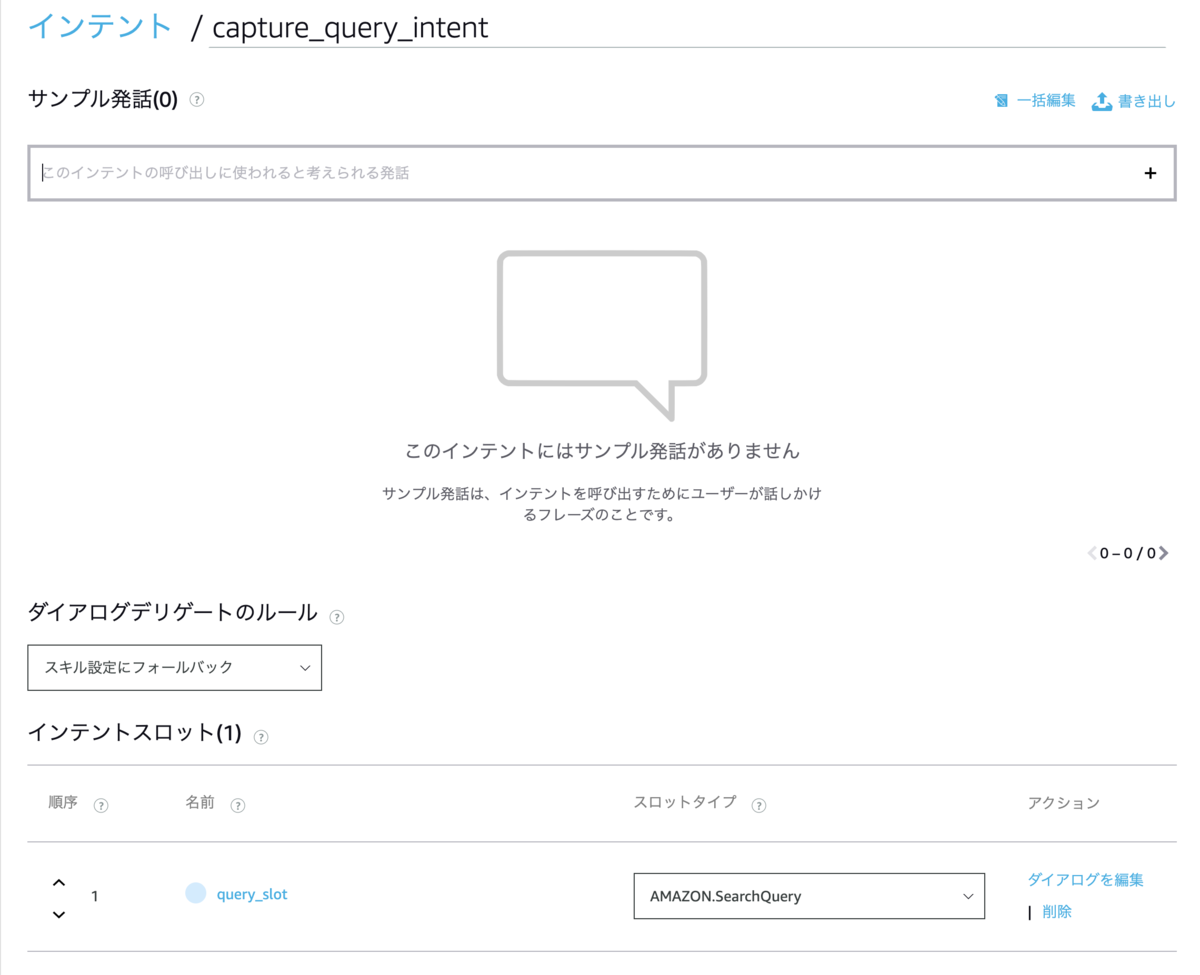
ただし、Alexaの場合、自由な発話の受け取りを使ったスキルを公開する場合、審査でどう判断されるかが正直わかりません。過去にもいろんなやり方がありましたが、審査基準が変わって使えなくなったりしたこともあると思うので、こればかりは審査に出してみないとわかりませんね。自由な発話はユーザがどういう発話をするかが想定できないので、プライバシーの観点でも注意が必要かなと思います。
まとめ
以前のCapture Step、難しい事を考えなくても簡単に使えるということで、最初のうちは多用しがちなのですが、実際にAlexaで動かしてみるとうまく動かない、特に意図しない発話の場合に正しくスロット値が取れない、ということでフォーラムなど問い合わせが多かったです。個人的には、インテント・サンプル発話・スロットをきちんと理解した上でChoice Stepを使うというのがベストプラクティスだと思うのですが、どうしてもここの部分のハードルは高いのかもしれません。
今回のアップデートにより、以前に比べるとシンプルさは薄れた感はありますが、それでもChoiceに比べると覚えることは少なくて済みますし、サンプル発話やNo Matchに対応したことにより意図しない発話にも対応できます。自由な発話を受け取れるのも便利ですね。
使い分けとしてはこんな感じになるかなと思います。
- Capture
- 一つのコンテキストの中で一つのスロットを収集したい
- 自由な発話を受け取りたい
- Choice
- 複数のコンテキストごとに、異なるスロットを収集して、分岐させたい
- 一つのコンテキストで複数のスロットを最小限の手間で確実に収集したい
会話のコンテキストやユースケースにあわせて使い分けると良いと思います!