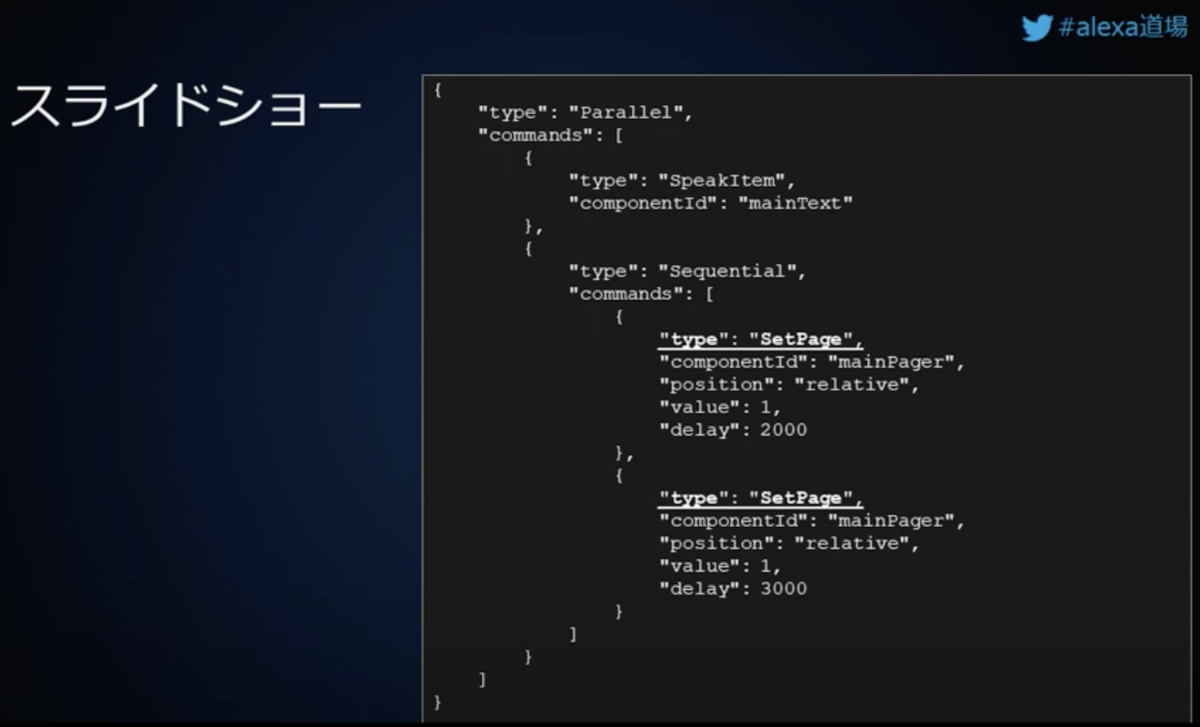
Voiceflowの新機能、「Directive Step」がAlexa・Google両方向けにリリースされましたので、ご紹介します。
これまでVoiceflowは各機能のことを「ブロック」といってきましたが、正式には「ステップ」という言い方に変わっていますので、今後は「ステップ」で統一します。
Directive Stepとは?
Directive Stepについては、以前APL for Audioのβテストでご紹介しています。
AlexaもGoogleも基本的に同じですが、スキルから返す発話させたい内容だけではなく、付加情報(例えば画面付きデバイス向けの画像や、回答のヒントなど)もセットにして返すことができます。これを「ディレクティブ」を言います。(厳密には「ディレクティブ」はAlexaでの言い方で、Googleでは発話させる内容も含めて「プロンプト」といいます。)
早速やってみましょう。
サンプルスキル
例によって、コーヒーショップの注文を受け付けるサンプルをGoogle向けプロジェクトで用意しました。

対話モデルもこんな感じで。


Directive Stepを使ってみる
Directive Stepはメニューの一番下にあります。

これをSpeakとChoiceの間に入れます。発話とセットで返すのが基本になるかと思いますので、Speakと一緒に使うことになると思います。

Directive Stepの設定画面はこんな感じです。マルっと入力欄だけがあって何をしていいのかわからないかもしれません。
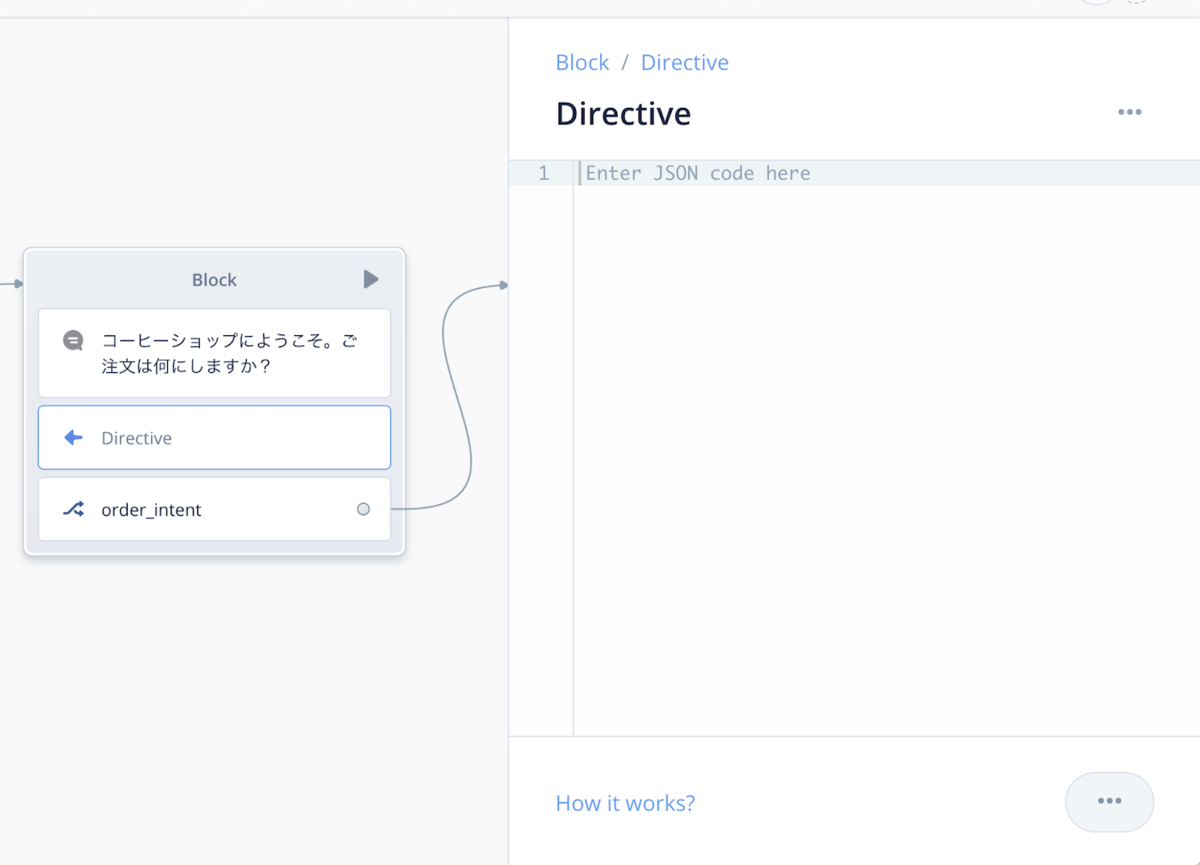
ここではVoiceflowの公式ドキュメントの手順に従ってやってみましょう。画像つきのカードを表示してみたいと思います。以下のような内容をDirerctive Stepの設定に記載します。
{ "content":{ "card":{ "title":"カードのタイトル", "subtitle":"カードのサブタイトル", "text":"カードのコンテンツ", "image":{ "alt":"画像の代替名", "height":0, "url":"https://developers.google.com/assistant/assistant_96.png", "width":0 } } } }

アップロードします。

テストシミュレータを開きます。

テストしてみましょう。発話も同時に、カードが表示されているのがわかりますでしょうか?

拡大するとこんな感じです。ちゃんと画像や説明が表示されていますね。

上記はスマートディスプレイ(Nest Hub等)での表示結果でした。一旦テストをキャンセルしてデバイスを"Phone"に変えてみましょう。


再度テストするとこのようにスマホ上での表示イメージが表示されます。

アクションの内容に合わせて内容や画像を変えるととこういう感じに表示できるということですね。

なお、画像は以下を利用させていただきました。ありがとうございます。
https://pixabay.com/images/id-1031526/
Directiveの設定方法
サンプルではカードを表示させるディレクティブを設定しましたが、いきなりではわからないですよね。ディレクティブの設定方法はGoogleのドキュメントを見るとわかります。
ここにプロンプト、つまり、Googleで返せるレスポンスの一覧が載っています。残念ながら日本語訳はまだないようです・・・

カードの場合はどうなっているかを見てみましょう。左のメニューの"Prompts"の"Rich"をクリックします。

少し下にスクロールすると、"Basic Card"というのがあります。表示例からもわかると思いますが、これが先ほどのサンプルで使った「カード」についての説明です。

さらにスクロールすると、設定できるプロパティの一覧があって・・・

さらに下にスクロールするとありました、サンプルコードです。

コードの種類がいくつかあるのですが、"JSON Builder"を選択します。

はい、これがカードのサンプルのレスポンスです。

ただし、これはレスポンス全体です。つまり、ディレクティブで設定するカード部分だけでなく、発話部分も含んでいます。Voiceflowの場合、発話はSpeak Stepがやってくれるので、こういうことになります。

つまり、発話以外の部分をコピーして、Directive Stepにペーストして修正すればよいということです。1点だけ注意すべきなのは、JSONはカッコにより階層構造が表現されています。Directive Stepに設定する場合は、
"content": { "card": { "title": "Card Title", "subtitle": "Card Subtitle", "text": "Card Content", "image": { "url": "https://developers.google.com/assistant/assistant_96.png", "alt": "Google Assistant logo" } } }
ではなく、以下のように外側を"{}"で囲んで、1階層下に設定する必要がある点にご注意ください。
{ // ココが必要 "content": { "card": { "title": "Card Title", "subtitle": "Card Subtitle", "text": "Card Content", "image": { "url": "https://developers.google.com/assistant/assistant_96.png", "alt": "Google Assistant logo" } } } } // ココが必要
いろいろなディレクティブがあるので、ぜひドキュメントを見て試してみてください!
まとめ
Alexaの場合、VoiceflowがいろいろなAlexa専用機能のステップを予め用意していることもあり、APL for Audioを使わない限り、Directive Stepを利用することは(現時点では)あまりないかもしれません。 Googleの場合は、独自のStepがあまり用意されていないこともあり、Directive Stepを使うと表現の幅が増えますし、特にスマホのGoogleアシスタントでリッチな表現ができるのが大きいです。
JSONのフォーマットを理解する必要があるため、少し技術的な内容になってしまいますが、がんばってぜひトライしてみてください!